Serverless computing, while offering unparalleled scalability and agility, introduces a new paradigm for security. The shift from managing infrastructure to focusing on code execution necessitates a re-evaluation of traditional security practices. Understanding and implementing robust security measures is paramount to protect serverless applications from a range of potential threats. This guide explores the essential security best practices for serverless architectures, equipping developers and security professionals with the knowledge to build secure and resilient applications.
This discussion will cover critical aspects of serverless security, including authentication and authorization, input validation, code security, network security, monitoring, secrets management, event source security, compliance, infrastructure as code security, and incident response planning. Each section will delve into specific vulnerabilities, recommended mitigation strategies, and practical examples to ensure a comprehensive understanding of the subject matter.
Serverless Architecture Overview
Serverless computing has emerged as a transformative paradigm in software development, promising to streamline operations and optimize resource utilization. This approach fundamentally alters how applications are built, deployed, and managed, shifting the focus from infrastructure management to code execution. This section will explore the foundational elements of serverless architecture, detailing its core concepts and components.
Fundamental Concepts of Serverless Computing
Serverless computing is a cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources. Developers write and deploy code without the need to provision or manage servers. The cloud provider automatically handles the scaling, availability, and management of the infrastructure required to run the code. This model allows developers to focus solely on writing code, while the cloud provider takes care of all the underlying infrastructure complexities.
Definition and Benefits of Serverless Architecture
Serverless architecture, in essence, is a cloud-native development model where the developer does not manage servers. The execution of application code is triggered by events, and resources are allocated dynamically. Key benefits of adopting serverless include:
- Reduced Operational Overhead: Developers are relieved of the burden of server provisioning, management, and scaling.
- Automatic Scaling: The infrastructure scales automatically based on demand, eliminating the need for manual intervention.
- Pay-per-Use Pricing: Users are charged only for the actual compute time and resources consumed, leading to potential cost savings.
- Increased Agility: Faster development cycles and quicker time to market due to simplified deployment and management processes.
- Improved Scalability: Applications can handle significant traffic spikes without performance degradation.
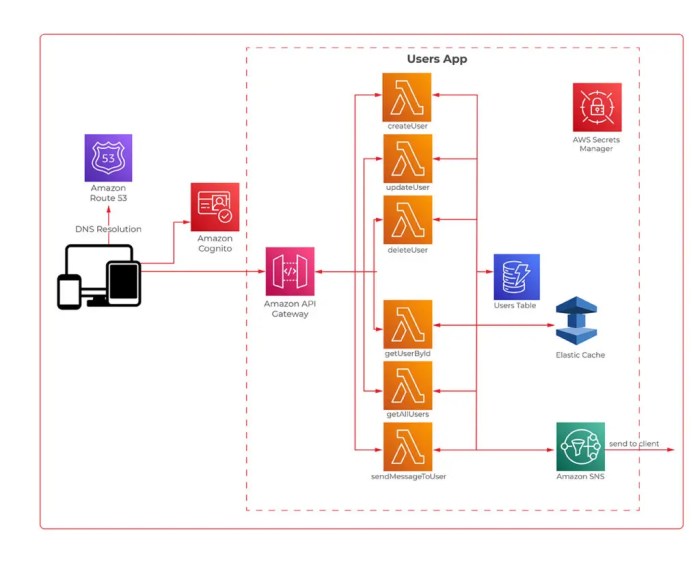
Core Components in a Serverless Environment
A typical serverless environment comprises several key components that work together to execute application logic. These components include:
- Functions as a Service (FaaS): This is the core component, representing the individual units of code that are executed in response to events. Examples include AWS Lambda, Azure Functions, and Google Cloud Functions. These functions are stateless and designed to execute quickly.
- Event Sources: These are triggers that initiate the execution of serverless functions. Examples include HTTP requests, database updates, file uploads, and scheduled events.
- API Gateway: This component acts as an entry point for API requests, handling routing, authentication, and other API management tasks. Examples include AWS API Gateway, Azure API Management, and Google Cloud API Gateway.
- Object Storage: Serverless applications often utilize object storage services for storing and retrieving data. Examples include AWS S3, Azure Blob Storage, and Google Cloud Storage.
- Databases: Serverless applications can integrate with various database services, including both relational and NoSQL databases. Examples include AWS DynamoDB, Azure Cosmos DB, and Google Cloud Firestore.
- Monitoring and Logging: Essential for tracking the performance and health of serverless applications. Services such as AWS CloudWatch, Azure Monitor, and Google Cloud Monitoring provide these capabilities.
Authentication and Authorization in Serverless
Securing access to serverless functions is paramount for maintaining the integrity and confidentiality of applications. This involves implementing robust mechanisms to verify the identity of users or services attempting to access functions (authentication) and then determining what resources they are permitted to access (authorization). These two processes work in tandem to ensure that only authorized entities can interact with serverless functions and their underlying resources, such as databases and storage.
Methods for Securing Access to Serverless Functions
Several methods are employed to secure access to serverless functions, each with its own advantages and considerations. The choice of method often depends on the specific application requirements, the complexity of the security needs, and the integration capabilities of the serverless platform being used.
- API Keys: API keys are simple access tokens that are often used to authenticate requests. The serverless function checks for the presence and validity of the API key in the request headers or query parameters. API keys are suitable for basic access control, such as limiting access to a service to a specific set of clients. However, API keys have security limitations because they are easily compromised and do not provide fine-grained control over user permissions.
- JSON Web Tokens (JWTs): JWTs are a standard for representing claims securely between two parties. They are widely used in serverless environments for authentication and authorization. A JWT is a digitally signed token containing information about the user or service, such as their identity and permissions. When a client requests access to a serverless function, it includes a JWT in the request. The function verifies the token’s signature to ensure its authenticity and then extracts the user’s claims to determine access permissions.
JWTs provide a flexible and secure way to manage authentication and authorization, especially when integrating with identity providers.
- OAuth 2.0 and OpenID Connect (OIDC): These are industry-standard protocols for authentication and authorization. OAuth 2.0 focuses on authorization, allowing a user to grant a third-party application access to their resources without sharing their credentials. OIDC builds on OAuth 2.0 to provide an identity layer, allowing applications to verify the identity of users. Serverless functions can integrate with OAuth 2.0 and OIDC providers, such as Google, Facebook, and Azure Active Directory, to authenticate users and manage access to resources.
This approach provides a secure and standardized way to manage user identities and permissions.
- Serverless Platform-Specific Authentication: Many serverless platforms provide built-in authentication mechanisms. For example, AWS Lambda can be integrated with Amazon Cognito, a user directory service. Azure Functions can integrate with Azure Active Directory. These platform-specific authentication services offer simplified authentication and authorization setup and management. These services often provide features such as user registration, login, password management, and multi-factor authentication.
- Web Application Firewall (WAF): A WAF acts as a shield, filtering and monitoring HTTP traffic between a web application and the internet. It can be used to protect serverless functions from various attacks, such as cross-site scripting (XSS) and SQL injection. WAFs can be configured to enforce access control policies, such as rate limiting and blocking requests from specific IP addresses or user agents.
Best Practices for Implementing Robust Authentication
Implementing robust authentication is critical for protecting serverless functions from unauthorized access. Several best practices should be followed to ensure the security and integrity of the authentication process.
- Use Strong Passwords: If using passwords for authentication, enforce strong password policies. This includes requiring a minimum length, the use of uppercase and lowercase letters, numbers, and special characters. Consider using a password strength checker to assess the quality of passwords.
- Implement Multi-Factor Authentication (MFA): MFA adds an extra layer of security by requiring users to provide multiple forms of verification. This could include a password and a one-time code from a mobile app or a hardware security key. MFA significantly reduces the risk of unauthorized access, even if the user’s password is compromised.
- Protect Credentials: Never store credentials directly in the serverless function code. Instead, store credentials securely in environment variables, secret management services, or configuration files. Regularly rotate credentials and limit access to them to authorized personnel only.
- Validate User Input: Always validate user input to prevent injection attacks. This includes sanitizing input to remove potentially malicious code. Use input validation libraries and frameworks to help prevent vulnerabilities.
- Implement Rate Limiting: Rate limiting restricts the number of requests a user or IP address can make within a specific time period. This helps to prevent brute-force attacks and denial-of-service (DoS) attacks. Configure rate limits at the API gateway level or within the serverless function itself.
- Monitor Authentication Activity: Implement logging and monitoring to track authentication attempts, including successful logins, failed logins, and suspicious activity. Use this data to detect and respond to security incidents.
- Regularly Update Dependencies: Keep the serverless function’s dependencies, including libraries and frameworks, up to date. Security vulnerabilities are often discovered in dependencies, and updating them is essential to patching security holes.
Authorization Strategies Suitable for Serverless Applications
Authorization determines what resources a user or service is allowed to access. Different authorization strategies are suitable for serverless applications, depending on the complexity of the application and the required level of access control.
- Role-Based Access Control (RBAC): RBAC assigns permissions to roles and then assigns users to those roles. This simplifies access management because permissions are managed at the role level, rather than individually for each user. RBAC is a common and effective authorization strategy for many serverless applications.
- Attribute-Based Access Control (ABAC): ABAC uses attributes of the user, the resource, and the environment to determine access permissions. This provides more fine-grained control than RBAC, allowing for complex authorization rules. ABAC is often used in applications with dynamic access control requirements.
- Policy-Based Authorization: This involves defining policies that specify access rules. Policies can be stored in a centralized location and enforced by the serverless functions. Policy-based authorization offers flexibility and centralized management of access control.
- Token-Based Authorization: In this approach, the client receives a token (e.g., a JWT) after successful authentication. The token contains information about the user’s identity and associated permissions. When the client requests access to a resource, it presents the token, and the serverless function validates the token and uses its claims to authorize the request.
Authentication Providers and Their Use Cases
The following table illustrates various authentication providers and their common use cases in serverless environments.
| Authentication Provider | Description | Use Cases |
|---|---|---|
| Amazon Cognito | A user directory service provided by AWS that allows you to add user sign-up, sign-in, and access control to your web and mobile apps. | Web and mobile applications built on AWS, social login, MFA, user identity management. |
| Azure Active Directory (Azure AD) | Microsoft’s cloud-based identity and access management service, enabling secure access to resources. | Applications within the Microsoft ecosystem, single sign-on (SSO), integration with Microsoft services, enterprise applications. |
| Google Identity Platform (Firebase Authentication) | Provides authentication services for web and mobile applications, including sign-in with email, password, phone, and social providers. | Web and mobile applications, social login, user identity management, integration with Google services. |
| Auth0 | A cloud-based identity platform that provides authentication and authorization services. | Web and mobile applications, SSO, multi-factor authentication, custom identity management. |
| Okta | A cloud-based identity and access management service. | Enterprise applications, SSO, multi-factor authentication, user lifecycle management. |
Input Validation and Data Sanitization
Input validation and data sanitization are critical security practices in serverless applications, designed to mitigate vulnerabilities stemming from untrusted data. Serverless functions, by their nature, often interact directly with user inputs, making them prime targets for attacks. Properly implementing these techniques is essential to safeguard data integrity, prevent malicious code execution, and maintain the overall security posture of the application.
Neglecting these practices can lead to severe consequences, including data breaches, system compromise, and denial-of-service attacks.
Common Input-Related Vulnerabilities in Serverless Applications
Serverless applications are susceptible to a range of input-related vulnerabilities. These vulnerabilities exploit weaknesses in how applications handle data received from various sources, including API requests, database entries, and event triggers. Understanding these vulnerabilities is the first step in designing effective mitigation strategies.
- Cross-Site Scripting (XSS): XSS attacks occur when malicious scripts are injected into web pages viewed by other users. In serverless environments, this can happen if user-supplied data, such as comments or form submissions, is not properly sanitized before being displayed. Attackers can inject JavaScript code that executes in the victim’s browser, potentially stealing session cookies, redirecting users, or defacing the website.
- SQL Injection (SQLi): SQLi attacks exploit vulnerabilities in database queries. If user input is directly incorporated into SQL queries without proper validation and sanitization, an attacker can inject malicious SQL code. This can lead to unauthorized access to sensitive data, modification or deletion of data, or even complete control of the database server.
- Command Injection: Command injection vulnerabilities arise when user input is used to construct system commands. If the input is not validated, an attacker can inject commands that the server executes. This could lead to the execution of arbitrary code on the server, potentially compromising the entire system.
- Path Traversal: Path traversal attacks, also known as directory traversal, allow attackers to access files and directories outside of the intended scope. If user input is used to construct file paths without proper validation, an attacker can manipulate the path to access sensitive files, such as configuration files or user credentials.
- Denial-of-Service (DoS): Malicious input can be used to overload serverless functions, leading to a denial-of-service condition. This can be achieved by submitting excessive amounts of data, complex data structures, or crafted input that causes the function to consume excessive resources, such as CPU time or memory.
- Insecure Deserialization: If serverless functions deserialize untrusted data without proper validation, attackers can exploit vulnerabilities in the deserialization process. This can lead to the execution of arbitrary code or other malicious actions.
Techniques for Effective Input Validation and Sanitization
Implementing robust input validation and data sanitization techniques is crucial for securing serverless applications. These techniques work together to ensure that only valid and safe data is processed by the application. The choice of techniques depends on the type of input and the context in which it is used.
- Input Validation: Input validation involves verifying that the input data conforms to expected formats, types, and ranges. This can be done at various stages, from the client-side to the server-side.
- Type Checking: Ensure that input data matches the expected data types (e.g., integers, strings, booleans). Use built-in functions or libraries to enforce type constraints.
- Format Validation: Verify that the input data conforms to specific formats, such as email addresses, dates, or phone numbers. Regular expressions can be a powerful tool for format validation.
- Range Validation: Check that numerical values fall within acceptable ranges. This prevents issues like buffer overflows and ensures that values are within the expected bounds.
- Length Validation: Limit the length of input strings to prevent excessive resource consumption or potential buffer overflows.
- Whitelisting: Define a list of acceptable values or patterns and reject anything that doesn’t match. Whitelisting is generally more secure than blacklisting because it prevents unexpected inputs.
- Data Sanitization: Data sanitization involves cleaning or transforming input data to remove or neutralize potentially harmful elements.
- HTML Encoding: Encode HTML special characters (e.g., ` <`, `>`, `&`, `”`) to prevent XSS attacks. Replace these characters with their HTML entities (e.g., `<`, `>`, `&`, `"`).
- SQL Escaping: Properly escape user input before incorporating it into SQL queries to prevent SQL injection attacks. Use parameterized queries or prepared statements to separate data from the SQL code.
- Command Escaping: Escape special characters in user input before passing it to system commands to prevent command injection attacks. Use functions or libraries specifically designed for command escaping.
- Path Sanitization: Validate and sanitize file paths to prevent path traversal attacks. Avoid using user input directly in file paths and use functions to normalize and sanitize the paths.
- Removal of Dangerous Characters: Remove or replace characters that are known to be malicious or could lead to vulnerabilities. For example, remove or escape control characters.
- Regular Expressions: Regular expressions (regex) are powerful tools for validating and sanitizing input data, particularly for format validation and pattern matching. They provide a concise way to define complex validation rules.
- Example (Email Validation): The regex `^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]2,$` can be used to validate email addresses. This expression checks for a valid format including the `@` symbol, domain name, and top-level domain.
- Example (Phone Number Validation): A regex like `^\(\d3\) \d3-\d4$` can validate US phone numbers in the format (XXX) XXX-XXXX.
- Context-Aware Validation and Sanitization: Tailor the validation and sanitization techniques to the specific context in which the input is used. For example, validation requirements for a username field will differ from those for a product description.
Procedure for Implementing Input Validation at Different Stages
Implementing input validation at multiple stages of a serverless function’s execution provides a layered defense against input-related vulnerabilities. This approach increases the overall security of the application and reduces the risk of successful attacks.
- Client-Side Validation: Perform initial validation on the client-side (e.g., in a web browser or mobile app) to provide immediate feedback to the user.
- Benefits: Improves user experience by providing instant feedback and reduces the load on the server.
- Limitations: Client-side validation can be bypassed, so it should not be the only layer of defense. Attackers can modify or disable client-side validation.
- API Gateway Validation: Utilize the API gateway (e.g., AWS API Gateway, Azure API Management) to validate incoming requests.
- Benefits: Acts as a central point for validation and can enforce consistent rules across all functions. Can filter out invalid requests before they reach the backend functions.
- Implementation: Define request schemas that specify the expected input format, data types, and other constraints. The API gateway can automatically validate requests against these schemas.
- Serverless Function Validation: Implement robust validation within the serverless function itself.
- Benefits: Provides a critical layer of defense against attacks that bypass client-side validation or API gateway validation. Allows for more specific and contextual validation rules.
- Implementation: Validate input data immediately after receiving it within the function’s code. Use the validation techniques described earlier (type checking, format validation, range validation, length validation, whitelisting, etc.).
- Database Validation: Implement validation at the database level, if applicable.
- Benefits: Protects the integrity of the database by ensuring that only valid data is stored.
- Implementation: Use database constraints (e.g., data types, unique constraints, not null constraints) to enforce data integrity. Consider using stored procedures that perform validation before inserting or updating data.
- Logging and Monitoring: Implement comprehensive logging and monitoring to detect and respond to potential security incidents.
- Logging: Log all input validation failures and suspicious activity. This helps identify potential attacks and provides valuable information for incident response.
- Monitoring: Monitor logs for anomalies and suspicious patterns. Set up alerts to notify security teams of potential threats.
Code Security and Vulnerability Management
Securing the code deployed within serverless functions is paramount to maintaining the integrity and confidentiality of the application and its data. Serverless environments, while offering benefits in terms of scalability and cost-effectiveness, introduce unique security challenges related to code management, dependencies, and runtime environments. This section details practices to fortify code security and manage vulnerabilities effectively in serverless architectures.
Securing Code Deployment
Securing the code deployed in serverless functions involves several key practices, from the initial development phase to the final deployment. This includes secure coding practices, version control, and the implementation of robust CI/CD pipelines.
- Secure Coding Practices: Employing secure coding standards minimizes the risk of introducing vulnerabilities. This includes avoiding hardcoded secrets, implementing proper error handling, and validating all input data. For example, instead of directly embedding API keys within the code, utilize environment variables. This allows for easier management and rotation of secrets without requiring code modifications.
- Version Control: Utilizing a version control system, such as Git, is essential for tracking code changes, collaborating with teams, and reverting to previous versions if needed. This provides a history of code modifications and allows for the identification of potential security breaches introduced through code changes.
- CI/CD Pipeline Integration: Integrating security checks into the CI/CD pipeline automates vulnerability detection early in the development process. Static code analysis, dependency scanning, and unit tests should be incorporated into the pipeline to identify and address security issues before deployment. For instance, a pipeline could automatically trigger a vulnerability scan using tools like Snyk or SonarQube after each code commit.
- Least Privilege Principle: Serverless functions should be granted only the minimum necessary permissions required for their operation. This reduces the potential impact of a compromised function. Implement Identity and Access Management (IAM) roles with the principle of least privilege, restricting access to only the resources and services needed by the function.
- Regular Code Reviews: Peer code reviews help identify potential security vulnerabilities, coding errors, and adherence to coding standards. This involves having other developers review the code for security flaws before it’s deployed.
Tools and Techniques for Vulnerability Scanning
Various tools and techniques are available for scanning serverless code for vulnerabilities. These tools analyze code, dependencies, and runtime configurations to identify potential security flaws.
- Static Application Security Testing (SAST): SAST tools analyze source code to identify vulnerabilities without executing the code. These tools examine the code for common security flaws, such as SQL injection, cross-site scripting (XSS), and insecure coding practices. Examples include SonarQube, and commercial tools like Veracode.
- Dynamic Application Security Testing (DAST): DAST tools test running applications to identify vulnerabilities. They simulate attacks against the application to identify security flaws that may not be apparent through static analysis. This involves the use of fuzzing and penetration testing techniques.
- Software Composition Analysis (SCA): SCA tools analyze the dependencies of a project to identify known vulnerabilities in third-party libraries and frameworks. These tools scan the project’s dependencies and compare them against a database of known vulnerabilities, such as the National Vulnerability Database (NVD). Examples include Snyk and OWASP Dependency-Check.
- Infrastructure as Code (IaC) Scanning: IaC scanning tools, such as those provided by tools like Terraform or CloudFormation, analyze the infrastructure code to identify misconfigurations that could lead to security vulnerabilities. These tools can detect issues like open security groups, overly permissive IAM roles, and insecure storage configurations.
- Container Scanning: If serverless functions use containerized runtimes, container scanning tools are essential for identifying vulnerabilities within the container images. Tools like Clair and Trivy scan container images for known vulnerabilities in the operating system and application dependencies.
Managing Dependencies and Patching Vulnerabilities
Effective dependency management and vulnerability patching are crucial for maintaining a secure serverless environment. This involves strategies for selecting, updating, and securing third-party libraries and frameworks.
- Dependency Selection: Carefully select dependencies based on their security track record, community support, and maintenance frequency. Prioritize dependencies that are actively maintained and have a good security reputation. Avoid using outdated or abandoned libraries, as they are more likely to contain vulnerabilities.
- Dependency Pinning: Pinning dependencies to specific versions ensures that the application uses a consistent set of libraries. This prevents unexpected behavior and potential security vulnerabilities introduced by updates. The use of a package manager, such as npm or pip, allows for specifying exact versions in a requirements file.
- Regular Dependency Updates: Regularly update dependencies to the latest versions to patch known vulnerabilities. Establish a process for monitoring and applying security patches promptly. Automated tools and notifications can assist in identifying and addressing outdated dependencies.
- Vulnerability Scanning and Monitoring: Continuously monitor dependencies for known vulnerabilities using SCA tools. Implement automated vulnerability scanning as part of the CI/CD pipeline and set up alerts to notify the team of any newly discovered vulnerabilities.
- Patch Management: Implement a systematic approach to patching vulnerabilities. Prioritize patching based on the severity of the vulnerability and its potential impact on the application. For critical vulnerabilities, consider immediate patching or mitigation strategies.
- Dependency Auditing: Regularly audit the dependencies used in the serverless functions. This involves reviewing the list of dependencies, their versions, and any known vulnerabilities. Dependency audits can identify unused or unnecessary dependencies that can be removed to reduce the attack surface.
Network Security Considerations
In serverless architectures, network security becomes critically important due to the distributed nature of functions and the inherent reliance on external services and APIs. The ephemeral nature of serverless functions and their interactions with various network components require a robust approach to secure communication, access control, and traffic management. Securing the network effectively protects against various threats, including unauthorized access, data breaches, and denial-of-service attacks.
Network Security Aspects in Serverless Context
Serverless network security involves protecting the communication channels between serverless functions, other services within the cloud environment, and external resources. Unlike traditional server infrastructure where network perimeters are more clearly defined, serverless applications require a more granular approach to network security. This involves understanding the attack surface, which includes ingress and egress traffic, the use of APIs, and the underlying infrastructure provided by the cloud provider.
The goal is to ensure confidentiality, integrity, and availability of data and services.
Strategies for Securing Network Traffic
Securing network traffic in serverless environments necessitates several strategies to protect data in transit and at rest. These strategies are often implemented through a combination of cloud provider features and best practices.
- Encryption in Transit: Implement Transport Layer Security (TLS) or Secure Sockets Layer (SSL) to encrypt all network traffic between serverless functions and other services or external resources. This prevents eavesdropping and man-in-the-middle attacks. For example, AWS Lambda functions can be configured to use HTTPS endpoints, and API Gateway supports TLS termination.
- Private Networking: Utilize private networking features such as Virtual Private Clouds (VPCs) to isolate serverless functions from the public internet. This restricts access to only authorized resources within the VPC. Functions can be deployed within a VPC to control network ingress and egress, and limit exposure to the public internet.
- API Gateway Security: Implement security measures within the API Gateway to protect API endpoints. This includes authentication, authorization, and rate limiting. API keys, OAuth, and custom authorizers can be used to control access. For example, AWS API Gateway offers features like request validation and throttling.
- Web Application Firewall (WAF): Employ a WAF to protect serverless functions from common web vulnerabilities, such as cross-site scripting (XSS) and SQL injection attacks. Cloud providers offer WAF services that can be integrated with API Gateways and other network components. For instance, AWS WAF can be used with API Gateway and CloudFront.
- Network Policies: Define network policies to control traffic flow between serverless functions and other services. These policies can specify which functions can communicate with each other and which external resources they can access. This is often achieved through security groups or network access control lists (ACLs).
Configuring Network Access Controls and Firewalls
Effective network access control and firewall configuration are essential for securing serverless environments. These controls define the rules for allowing or denying network traffic to and from serverless functions.
- Security Groups: Configure security groups to control inbound and outbound traffic for serverless functions. Security groups act as virtual firewalls, allowing only authorized traffic to reach the functions. For example, you can create a security group that only allows inbound traffic from a specific API Gateway or other trusted sources.
- Network Access Control Lists (ACLs): Use network ACLs to provide an additional layer of security at the subnet level. ACLs can be used to allow or deny traffic based on IP addresses, protocols, and port numbers. Network ACLs operate independently of security groups and can be used to enforce stricter access controls.
- Firewall Rules: Configure firewall rules to control network traffic based on various criteria, such as source and destination IP addresses, ports, and protocols. Firewall rules can be implemented using cloud provider-specific firewall services or third-party solutions. For instance, AWS Firewall Manager can be used to centrally manage firewall rules across multiple accounts and regions.
- Least Privilege Principle: Apply the principle of least privilege when configuring network access controls. Grant only the necessary permissions to serverless functions and other resources to perform their intended tasks. This minimizes the attack surface and reduces the potential impact of a security breach.
- Regular Auditing and Monitoring: Regularly audit and monitor network access controls and firewall configurations to ensure they are up-to-date and effective. Implement logging and alerting to detect and respond to any unauthorized access attempts or suspicious network activity.
Monitoring and Logging Best Practices
Monitoring and logging are critical components of serverless application security and operational excellence. They provide visibility into the application’s behavior, performance, and security posture, enabling proactive identification and resolution of issues. Effective monitoring and logging allow for the detection of anomalies, security threats, and performance bottlenecks, ensuring the application remains reliable, secure, and efficient. The ability to trace requests, understand user behavior, and troubleshoot errors is significantly enhanced through well-implemented monitoring and logging strategies.
Significance of Monitoring and Logging in Serverless Environments
Monitoring and logging are essential in serverless environments due to their ephemeral nature and distributed architecture. Unlike traditional infrastructure where servers are managed, serverless functions are short-lived and executed on demand. This necessitates a shift in how applications are observed and debugged.
- Real-time Visibility: Monitoring provides real-time insights into the health and performance of serverless functions, API gateways, and other related services.
- Anomaly Detection: Logging and monitoring enable the identification of unusual patterns or deviations from the expected behavior, which may indicate security breaches or performance issues.
- Troubleshooting and Debugging: Comprehensive logs facilitate the diagnosis of errors, tracing of requests, and identification of the root cause of problems.
- Performance Optimization: Monitoring tools can track key performance indicators (KPIs), such as latency, execution time, and resource utilization, enabling performance optimization.
- Security Incident Response: Logging and monitoring are crucial for detecting and responding to security incidents, such as unauthorized access attempts or malicious activity.
Essential Metrics to Monitor for Serverless Applications
Monitoring a serverless application requires tracking several key metrics to understand its performance, health, and security posture. These metrics provide valuable insights into various aspects of the application’s behavior.
- Invocation Count: The number of times a function is executed. This metric helps to understand the workload and usage patterns.
- Execution Duration: The time it takes for a function to complete its execution. High execution durations can indicate performance bottlenecks.
- Cold Start Duration: The time it takes for a function to start when it hasn’t been recently used. Monitoring cold start times is crucial for minimizing latency.
- Error Rate: The percentage of function invocations that result in errors. A high error rate indicates potential issues with the code or dependencies.
- Throttling Errors: The number of times a function is throttled due to exceeding resource limits. Throttling errors can impact performance and availability.
- Concurrency: The number of concurrent function invocations. Monitoring concurrency helps to understand resource utilization and prevent overloading.
- Memory Utilization: The amount of memory used by a function during execution. Monitoring memory utilization helps to identify memory leaks or inefficient code.
- API Gateway Latency: The time it takes for requests to be processed by the API gateway. High latency can impact user experience.
- Data Transfer: The amount of data transferred in and out of the serverless functions. This metric is essential for cost optimization.
Example of a Log Structure for a Serverless Function Invocation
A well-structured log format is crucial for efficient analysis and troubleshooting in serverless environments. The following example illustrates a structured log entry for a serverless function invocation, leveraging JSON format for easy parsing and analysis.
"timestamp": "2024-02-29T10:30:00Z", "level": "INFO", "requestId": "a1b2c3d4-e5f6-7890-1234-567890abcdef", "functionName": "processOrder", "functionVersion": "$LATEST", "message": "Order processing initiated", "userId": "user123", "orderId": "ORD-12345", "input": "productId": "P-123", "quantity": 2 , "executionTime": 0.25, "memoryUsed": 128, "status": "SUCCESS", "statusCode": 200
The example log structure includes the following key fields:
- timestamp: The date and time the log event occurred.
- level: The severity of the log event (e.g., INFO, WARNING, ERROR).
- requestId: A unique identifier for the request.
- functionName: The name of the serverless function.
- functionVersion: The version of the serverless function.
- message: A descriptive message about the event.
- userId: The identifier of the user associated with the request.
- orderId: The identifier of the order being processed.
- input: The input data passed to the function.
- executionTime: The duration of the function execution in seconds.
- memoryUsed: The amount of memory used by the function in MB.
- status: The outcome of the function execution (e.g., SUCCESS, FAILURE).
- statusCode: The HTTP status code returned by the function.
Secrets Management

Securing sensitive information, such as API keys, database credentials, and cryptographic keys, is paramount in serverless applications. Improperly managed secrets can lead to unauthorized access, data breaches, and significant security vulnerabilities. Implementing robust secrets management practices is essential for maintaining the confidentiality, integrity, and availability of serverless applications.
Secure Storage and Management of Secrets
The secure storage and management of secrets in serverless environments involve several key principles and techniques to protect sensitive information from unauthorized access. This includes encryption, access control, and regular rotation.
- Encryption: Secrets should always be encrypted both in transit and at rest. In transit encryption can be achieved through the use of HTTPS/TLS when transmitting secrets between services or systems. At rest encryption protects secrets when they are stored in a secrets management service or other storage mechanisms. This encryption typically uses industry-standard encryption algorithms like AES-256.
- Access Control: Implement strict access control mechanisms to restrict access to secrets based on the principle of least privilege. Only authorized identities (e.g., roles, users, services) should have access to specific secrets. Utilize Identity and Access Management (IAM) policies and roles to define these permissions.
- Secrets Storage: Secrets should never be hardcoded directly into the application code or stored in configuration files that are version-controlled. Instead, use a dedicated secrets management service or secure storage solution. This separation of secrets from code significantly reduces the risk of exposure.
- Auditing: Implement comprehensive auditing and logging of secret access and changes. This allows for monitoring of who accessed which secrets, when, and from where. Audit logs can be used to detect suspicious activities and investigate potential security incidents.
- Key Rotation: Regularly rotate secrets, such as API keys and database passwords, to minimize the impact of a potential compromise. Automated rotation processes should be implemented to reduce the manual effort and the risk of human error.
Secrets Management Services for Serverless Platforms
Several secrets management services are specifically designed for serverless platforms, providing secure storage, access control, and management capabilities.
- AWS Secrets Manager: AWS Secrets Manager is a fully managed secrets management service offered by Amazon Web Services. It allows you to store, retrieve, and manage secrets, and automatically rotate them. AWS Secrets Manager supports a wide range of secrets, including database credentials, API keys, and SSH keys. It integrates seamlessly with other AWS services, such as Lambda, API Gateway, and EC2.
The service provides features like automatic rotation of secrets, which can be configured for various database types and services.
- AWS Systems Manager Parameter Store: Although primarily a configuration management service, AWS Systems Manager Parameter Store can also be used to store secrets securely. Secrets are stored as parameters and can be encrypted using KMS keys. Parameter Store provides access control and versioning features. While not as feature-rich as Secrets Manager, it is a cost-effective option for simpler secret management needs.
- Google Cloud Secret Manager: Google Cloud Secret Manager is a fully managed secrets management service on Google Cloud Platform (GCP). It allows you to securely store, manage, and access secrets, such as API keys, passwords, and certificates. Google Cloud Secret Manager offers features such as encryption at rest, access control with IAM, versioning, and automatic secret rotation. It integrates with other GCP services, including Cloud Functions, Cloud Run, and Kubernetes Engine.
- Azure Key Vault: Azure Key Vault is a cloud service provided by Microsoft Azure for securely storing and managing secrets, encryption keys, and certificates. It offers features such as access control, key rotation, and auditing. Azure Key Vault integrates with other Azure services, such as Azure Functions, Logic Apps, and Virtual Machines. It supports a wide range of secret types, including passwords, API keys, and certificates.
- HashiCorp Vault: HashiCorp Vault is a widely used open-source secrets management solution that can be deployed on various platforms, including serverless environments. It provides a centralized platform for storing, managing, and accessing secrets, with features like encryption, access control, and auditing. Vault offers a high degree of flexibility and can integrate with multiple cloud providers and on-premises systems.
Procedure for Automatic Secret Rotation
Automated secret rotation is a critical security practice that involves periodically changing secrets to mitigate the risk of compromise. Implementing an automated secret rotation procedure reduces the manual effort required and the potential for human error.
- Choose a Secrets Management Service: Select a secrets management service that supports automatic secret rotation. Services like AWS Secrets Manager, Google Cloud Secret Manager, and Azure Key Vault provide built-in capabilities for rotating secrets.
- Define Rotation Schedule: Establish a rotation schedule based on the sensitivity of the secret and the risk tolerance of the organization. Common rotation frequencies include every 30, 60, or 90 days.
- Implement Rotation Logic: For each secret, create a rotation function or script. This function will handle the following tasks:
- Generate a new secret.
- Update the secret in the target service (e.g., database, API).
- Update the secret in the secrets management service.
- Test the new secret to ensure it is working correctly.
- Configure Triggers: Set up triggers to automatically execute the rotation function according to the defined schedule. These triggers can be based on time-based events or specific events within the application or infrastructure. For example, AWS Secrets Manager can trigger a Lambda function to rotate secrets on a schedule.
- Monitor and Alert: Implement monitoring and alerting to track the success or failure of secret rotation. Receive notifications when rotations fail and investigate the cause. Also, monitor access to the secrets to identify potential misuse.
Event Source Security
Event-driven architectures, a cornerstone of serverless computing, introduce unique security challenges. The inherent asynchronous nature of event processing and the diverse sources triggering these events necessitate a robust security posture. Compromising an event source can lead to a cascade of vulnerabilities, potentially impacting the entire application and the data it processes. Therefore, a comprehensive understanding of event source security is crucial for building secure and resilient serverless applications.
Security Considerations for Event Sources
Event sources, the originators of events that trigger serverless functions, require careful security assessments. The security posture of an event source directly influences the overall security of the serverless application. Several key considerations must be addressed to mitigate risks.
- Authentication and Authorization: Verify the identity of the event source and authorize its access to trigger functions. This prevents unauthorized actors from injecting malicious events.
- Data Validation and Sanitization: Ensure that data from the event source is validated and sanitized before being processed by the function. This mitigates risks such as injection attacks and data corruption.
- Rate Limiting and Throttling: Implement rate limiting and throttling mechanisms to prevent abuse and denial-of-service (DoS) attacks. This helps to control the volume of events and protect function resources.
- Encryption: Employ encryption, both in transit and at rest, to protect sensitive data within the event payload. This safeguards data confidentiality.
- Monitoring and Auditing: Implement robust monitoring and auditing capabilities to detect and respond to security incidents. This provides visibility into event activity and helps identify potential threats.
Risks Associated with Different Event Triggers
Different event triggers present varying security risks, each requiring tailored mitigation strategies. Understanding these risks is critical for implementing effective security controls.
- HTTP/API Gateway: The primary risk here is malicious input through crafted HTTP requests. This can lead to injection attacks (e.g., SQL injection, cross-site scripting), unauthorized access, and data breaches. Consider the following:
- Implement input validation and sanitization at the API gateway level.
- Enforce strong authentication and authorization mechanisms.
- Use rate limiting and request throttling to prevent DoS attacks.
- Message Queues (e.g., SQS, Kafka): Risks include message injection, replay attacks, and unauthorized access to queue data. Mitigation strategies include:
- Authenticate message producers and consumers.
- Encrypt messages in transit and at rest.
- Implement message authentication and digital signatures.
- Monitor queue activity for suspicious patterns.
- Object Storage (e.g., S3): Risks involve unauthorized object access, malicious object uploads, and data exfiltration. To mitigate these, consider:
- Implement access control lists (ACLs) and bucket policies to restrict access.
- Enable versioning and object locking to prevent data tampering.
- Use object scanning for malware detection.
- Monitor object activity for suspicious events (e.g., excessive downloads).
- Databases (e.g., DynamoDB, PostgreSQL): Database triggers can be exploited to execute malicious code or manipulate data. Mitigation strategies include:
- Validate and sanitize data before database operations.
- Implement least privilege access for database users.
- Monitor database activity for suspicious patterns.
- Regularly audit database configurations and security settings.
- Scheduled Events (e.g., CloudWatch Events, Cron jobs): Risks involve the execution of unauthorized or malicious code. To address these:
- Verify the integrity of the code being executed.
- Implement proper access controls to the code repository.
- Monitor event logs for unexpected behavior.
- Ensure that the execution environment is secure.
Methods to Secure Event-Driven Architectures
Securing event-driven architectures requires a multi-layered approach that encompasses various security controls. The effectiveness of the security implementation relies on a combination of techniques applied throughout the event lifecycle.
- Authentication and Authorization Enforcement: Implement robust authentication and authorization mechanisms at the event source and within the serverless function. Use Identity and Access Management (IAM) roles and policies to control access to resources.
- Input Validation and Data Sanitization: Validate and sanitize all data received from event sources. Use regular expressions, schema validation, and other techniques to filter out malicious input.
- Rate Limiting and Throttling Implementation: Implement rate limiting and throttling mechanisms to prevent abuse and DoS attacks. This limits the number of events processed within a given timeframe.
- Encryption Strategy: Encrypt sensitive data both in transit and at rest. Use HTTPS for secure communication between event sources and functions. Employ encryption keys and key management services.
- Monitoring and Logging Best Practices: Implement comprehensive monitoring and logging to track event activity and detect anomalies. Collect logs from all components of the event-driven architecture. Analyze logs for suspicious patterns.
- Security Auditing and Compliance: Regularly audit the security configuration of event sources and serverless functions. Ensure compliance with relevant security standards and regulations.
- Event Source Filtering and Routing: Filter and route events based on predefined rules and security policies. This helps to isolate malicious events and prevent them from reaching sensitive resources. For instance, implement a filtering mechanism at the API Gateway level to reject requests from suspicious IP addresses or with malformed data.
- Use of Security-Focused Services: Leverage security-focused services offered by cloud providers, such as Web Application Firewalls (WAFs), intrusion detection systems (IDS), and security information and event management (SIEM) solutions. For example, integrate a WAF with an API Gateway to protect against common web attacks like SQL injection and cross-site scripting.
Compliance and Regulatory Requirements

Serverless architectures, while offering numerous advantages, introduce complexities when it comes to achieving and maintaining compliance with various regulations. The distributed nature of serverless applications, coupled with the shared responsibility model inherent in cloud environments, necessitates a meticulous approach to security and compliance. Successfully navigating these requirements involves understanding the specific regulations applicable to your data and operations, implementing appropriate security controls, and continuously monitoring and auditing your serverless environment.
This section provides a comprehensive overview of the key considerations for achieving compliance in a serverless setup.
Achieving Compliance in a Serverless Setup
Achieving compliance in a serverless environment requires a multi-faceted approach that considers the unique characteristics of the architecture. It’s not just about ticking boxes; it’s about building a secure and compliant system from the ground up. This involves careful planning, diligent implementation, and ongoing monitoring.
The process can be broken down into the following key steps:
- Identify Applicable Regulations: Determine which regulations apply to your business and the data you handle. This could include HIPAA (for healthcare data), GDPR (for personal data of EU citizens), PCI DSS (for payment card information), or other industry-specific or geographic-specific regulations. Understanding the scope and requirements of each regulation is the first and most crucial step.
- Assess Current State: Evaluate your current serverless architecture against the identified regulations. This involves identifying gaps in your security posture and areas that require improvement. This assessment should cover all aspects of your serverless application, from code and infrastructure to data storage and access controls.
- Implement Security Controls: Implement the necessary security controls to address the identified gaps. This includes implementing access controls, encryption, data loss prevention measures, and audit trails. These controls should be integrated into your serverless application and infrastructure.
- Automate and Monitor: Automate as much of the security and compliance process as possible. This includes automated testing, monitoring, and alerting. Continuous monitoring is essential to detect and respond to security threats and compliance violations.
- Document and Audit: Maintain comprehensive documentation of your security controls and compliance efforts. Regular audits are essential to verify that your controls are effective and that you are meeting the requirements of the regulations. This documentation is critical for demonstrating compliance to auditors and regulators.
Security Considerations for Various Compliance Standards
Different compliance standards have unique security requirements. Understanding these differences is crucial for tailoring your security controls to meet the specific needs of each standard. This comparison highlights key security considerations for HIPAA, GDPR, and PCI DSS.
| Compliance Standard | Key Security Considerations |
|---|---|
| HIPAA (Health Insurance Portability and Accountability Act) |
|
| GDPR (General Data Protection Regulation) |
|
| PCI DSS (Payment Card Industry Data Security Standard) |
|
Examples of Security Controls to Address Compliance Requirements
Implementing specific security controls is essential to meet the requirements of various compliance standards. The following examples illustrate how to address compliance requirements in a serverless environment. These examples are applicable across multiple standards, with the specific implementation details varying based on the specific regulation and the serverless platform used.
- Access Control: Implement role-based access control (RBAC) to restrict access to sensitive data and resources. This involves defining roles and permissions based on the principle of least privilege.
- Encryption: Use encryption both in transit (e.g., HTTPS for API calls) and at rest (e.g., encrypting data stored in databases or object storage). Encryption is critical for protecting sensitive data.
For example, in AWS, you can use KMS (Key Management Service) to manage encryption keys for encrypting data in S3 (Simple Storage Service) or DynamoDB.
- Input Validation and Data Sanitization: Implement robust input validation and data sanitization techniques to prevent injection attacks (e.g., SQL injection, cross-site scripting). This helps to protect against data breaches and ensures data integrity.
For instance, use a Web Application Firewall (WAF) like AWS WAF to filter malicious traffic.
- Logging and Monitoring: Implement comprehensive logging and monitoring to track all activities within the serverless environment. This includes logging API calls, database access, and other critical events.
Use a centralized logging service like AWS CloudWatch to collect and analyze logs.
- Audit Trails: Implement audit trails to track all access to and modifications of sensitive data. This provides an auditable record of all activities, which is essential for compliance.
Enable CloudTrail to log API calls made to your AWS account, which can be used to track user activity.
- Vulnerability Scanning and Penetration Testing: Regularly scan your serverless applications and infrastructure for vulnerabilities. Conduct penetration testing to identify and address security weaknesses. This helps to identify and mitigate security risks before they can be exploited.
Use tools like OWASP ZAP or commercial vulnerability scanners to identify vulnerabilities in your serverless applications.
Infrastructure as Code (IaC) Security
Infrastructure as Code (IaC) is crucial for serverless security, automating infrastructure provisioning and configuration. This automation minimizes human error, promotes consistency, and allows for the implementation of security controls throughout the infrastructure lifecycle. Secure IaC practices are essential for protecting serverless applications from vulnerabilities and ensuring compliance.
Importance of IaC for Security in Serverless Deployments
IaC significantly enhances security in serverless environments by enabling repeatable, auditable, and version-controlled infrastructure deployments. This approach allows security policies to be codified and enforced consistently across all environments.
IaC’s contributions to serverless security are substantial:
- Automated Security Enforcement: IaC allows the definition and automatic enforcement of security policies. Security configurations are applied consistently across all deployments, reducing the risk of misconfigurations.
- Reduced Human Error: Manual infrastructure provisioning is prone to human error. IaC automates this process, minimizing the potential for mistakes that could introduce security vulnerabilities.
- Version Control and Auditing: IaC configurations are stored in version control systems, enabling tracking of changes, facilitating audits, and allowing for rollbacks to previous, secure states. This provides a clear audit trail of infrastructure changes.
- Consistency and Repeatability: IaC ensures consistent infrastructure deployments across all environments (development, testing, production). This consistency simplifies security testing and reduces the likelihood of environment-specific vulnerabilities.
- Faster Remediation: When vulnerabilities are identified, IaC allows for rapid remediation by updating the infrastructure templates and redeploying. This speeds up the patching process and minimizes the window of exposure.
Integrating Security Checks into the IaC Pipeline
Integrating security checks into the IaC pipeline is essential for proactively identifying and mitigating vulnerabilities before deployment. This process ensures that security is built into the infrastructure from the outset.
Integrating security checks involves several key steps:
- Static Analysis: Utilize tools to scan IaC templates for security vulnerabilities, misconfigurations, and compliance violations. Tools like `tfsec` (for Terraform), `cfn-lint` (for CloudFormation), and `checkov` (supports multiple IaC formats) analyze the code without executing it. These tools examine the templates for security best practices.
- Dynamic Analysis: After deployment, use tools to scan the deployed infrastructure for vulnerabilities and misconfigurations. This approach validates the actual infrastructure configuration against security policies. Tools such as `CloudSploit` and cloud provider-specific security scanners can be employed.
- Policy as Code: Define security policies as code using tools like Open Policy Agent (OPA). This allows you to enforce custom security rules and ensure that IaC templates comply with organizational policies.
- Automated Testing: Integrate security testing into the CI/CD pipeline. This ensures that every IaC change is automatically checked for security vulnerabilities before deployment.
- Vulnerability Scanning: Scan infrastructure components (e.g., container images) for known vulnerabilities. This identifies and mitigates vulnerabilities that may be present in the deployed infrastructure.
- Shift Left Approach: Implement security checks early in the development lifecycle. This approach reduces the cost and effort required to remediate vulnerabilities.
Guide to Secure IaC Templates
Creating secure IaC templates requires adhering to security best practices throughout the template development process. This includes following secure coding practices, using least privilege, and implementing robust monitoring.
A comprehensive guide to secure IaC templates includes:
- Principle of Least Privilege: Grant only the necessary permissions to infrastructure resources. Avoid using overly permissive roles and policies. This minimizes the impact of potential security breaches.
- Input Validation and Sanitization: Validate and sanitize all user inputs to prevent injection attacks (e.g., SQL injection, command injection). This protects against malicious code being injected into the infrastructure.
- Secure Storage of Secrets: Store sensitive information (e.g., API keys, passwords) securely using secret management services. Avoid hardcoding secrets directly into the IaC templates.
- Encryption: Encrypt data at rest and in transit. Implement encryption for storage volumes, databases, and network traffic. This protects sensitive data from unauthorized access.
- Regular Updates and Patching: Keep all software components up-to-date with the latest security patches. This mitigates known vulnerabilities.
- Monitoring and Logging: Implement comprehensive monitoring and logging to detect and respond to security incidents. Monitor infrastructure resources for suspicious activity.
- Compliance with Security Standards: Adhere to industry-specific security standards and best practices (e.g., CIS Benchmarks, NIST). This ensures that infrastructure meets regulatory requirements.
- Use of Secure Modules and Templates: Utilize pre-built, secure modules and templates from trusted sources. These resources often incorporate security best practices and can save time and effort.
- Version Control: Use version control to track changes to IaC templates. This enables auditing, rollback, and collaboration.
- Regular Security Audits: Conduct regular security audits of IaC templates and deployed infrastructure. This helps identify and address potential vulnerabilities.
Incident Response Planning
Developing a robust incident response plan is critical for serverless applications. The ephemeral nature of serverless functions and the distributed architecture necessitate a proactive and well-defined strategy to identify, contain, eradicate, recover from, and learn from security incidents. A comprehensive plan minimizes damage, reduces downtime, and maintains trust.
Components of an Incident Response Plan
A comprehensive incident response plan encompasses several key components, ensuring a structured and effective response to security breaches. These components work together to guide the response team through each phase of an incident.
- Preparation: This phase involves establishing policies, procedures, and tools to prepare for potential security incidents. It includes:
- Defining roles and responsibilities for the incident response team (IRT).
- Establishing communication channels (e.g., Slack channels, on-call rotations).
- Implementing security monitoring and alerting systems.
- Creating and maintaining a secure baseline for serverless function deployments.
- Conducting regular training and simulations for the IRT.
- Identification: This stage focuses on detecting and confirming security incidents. It involves:
- Monitoring logs and security alerts from various sources (e.g., cloud provider logs, function logs, API gateway logs).
- Analyzing suspicious activities and anomalies.
- Validating alerts and classifying incidents based on severity.
- Identifying the scope and impact of the incident.
- Containment: The goal of containment is to limit the damage caused by the incident. This includes:
- Isolating affected resources (e.g., disabling compromised functions, revoking access keys).
- Halting malicious activities.
- Preserving evidence for forensic analysis.
- Eradication: This phase involves removing the cause of the incident. It includes:
- Removing malware or malicious code.
- Patching vulnerabilities.
- Restoring compromised systems to a known good state.
- Recovery: The recovery phase focuses on restoring normal operations. This includes:
- Deploying clean versions of functions.
- Restoring data from backups.
- Verifying the integrity of recovered systems.
- Post-Incident Activity: After the incident is resolved, the post-incident phase focuses on learning from the experience. This includes:
- Conducting a post-incident review to identify root causes and lessons learned.
- Updating the incident response plan and security policies.
- Implementing preventive measures to avoid similar incidents in the future.
- Improving monitoring and alerting capabilities.
Checklist of Steps in Case of a Security Incident
A well-defined checklist ensures that the incident response team follows a structured approach during a security incident. This checklist should be readily accessible and tailored to the specific serverless environment.
- Detection and Validation:
- Verify the alert and determine the severity.
- Gather initial evidence (logs, network traffic).
- Notify the incident response team.
- Assessment and Scoping:
- Identify affected resources and the scope of the impact.
- Determine the root cause of the incident.
- Assess the potential damage.
- Containment:
- Isolate compromised functions or resources.
- Disable or revoke compromised credentials.
- Implement temporary security measures.
- Eradication:
- Remove malicious code or files.
- Patch vulnerabilities.
- Remove attacker access.
- Recovery:
- Restore from backups if necessary.
- Re-deploy clean versions of functions.
- Verify system integrity.
- Post-Incident Activities:
- Conduct a post-incident review.
- Update the incident response plan.
- Implement preventive measures.
- Document all actions and findings.
Incident Response Workflow Diagram
A visual representation of the incident response workflow helps the incident response team understand the flow of actions during an incident. The diagram clarifies the sequence of steps, responsibilities, and decision points.
Diagram Description: The diagram illustrates a cyclical workflow, beginning with incident detection. The cycle progresses through the following stages: Detection, Analysis, Containment, Eradication, Recovery, and Post-Incident Activity. Each stage includes specific actions and decision points. For example, after detection, analysis determines the severity and impact, leading to containment strategies like isolating compromised functions. The cycle culminates in post-incident review, which feeds back into the preparation phase, ensuring continuous improvement.
Arrows indicate the flow between stages, highlighting dependencies and iterative processes.
Final Review
In conclusion, securing serverless applications demands a proactive and multifaceted approach. By implementing the security best practices Artikeld in this guide, organizations can mitigate risks, ensure compliance, and maintain the integrity of their serverless deployments. From robust authentication mechanisms to proactive incident response plans, the principles discussed provide a framework for building secure, scalable, and resilient serverless architectures. Embracing these practices is not merely a recommendation but a critical imperative for realizing the full potential of serverless computing.
Question & Answer Hub
What is the biggest security risk in serverless?
The biggest security risk in serverless is often the lack of visibility and control over the underlying infrastructure. Developers often cede control of the infrastructure to the cloud provider, leading to potential misconfigurations and vulnerabilities that are difficult to detect and remediate without proper monitoring and security tools.
How does serverless change the approach to security?
Serverless changes the security approach by shifting the focus from infrastructure security to application security. Developers must concentrate on securing the code, data, and event triggers, rather than managing servers and network configurations. This requires adopting new tools and techniques to address the unique challenges of a serverless environment.
What are the key differences in security between serverless and traditional applications?
Key differences include the need for more granular access control, the importance of securing event triggers, the reliance on third-party services for security, and the increased focus on code-level security. Traditional applications often have a more defined perimeter, while serverless applications are more distributed and rely on a different security model.
How can I test the security of my serverless functions?
You can test the security of your serverless functions using various methods, including static code analysis, dynamic application security testing (DAST), penetration testing, and fuzzing. It is essential to integrate security testing into the CI/CD pipeline to identify and address vulnerabilities early in the development process.
Is serverless more or less secure than traditional applications?
Serverless can be both more and less secure than traditional applications. It offers enhanced security features, such as automated patching and infrastructure management, but also introduces new attack vectors and challenges. The overall security depends on how well the best practices are implemented and the security posture of the development team.