The integration of API Gateway with Lambda functions presents a paradigm shift in building scalable and efficient RESTful APIs. This architectural pattern, rooted in serverless computing principles, allows developers to construct robust API backends without the operational overhead of managing servers. The synergy between these services facilitates rapid development cycles, cost optimization, and improved resource utilization, making it a compelling choice for modern application development.
This discussion will dissect the intricacies of this integration, covering the essential components and configurations required to establish a fully functional RESTful API. From the initial setup of API Gateway endpoints and the creation of Lambda functions to advanced topics such as authentication, request validation, and performance optimization, we will provide a comprehensive understanding of the underlying mechanisms and best practices.
Introduction to API Gateway and Lambda Functions
Building scalable and efficient RESTful APIs in modern cloud environments necessitates a robust infrastructure. This typically involves managing request routing, authentication, authorization, and handling the actual business logic. Utilizing API Gateway and Lambda functions together provides a powerful and cost-effective solution for this purpose.API Gateway serves as the front door for all API requests, acting as a central point of entry and traffic management system.
Lambda functions are serverless compute services that execute code in response to events, like API calls. This combination enables developers to build highly scalable, resilient, and pay-per-use APIs.
Core Functionalities of an API Gateway
API Gateway is a fully managed service that acts as an intermediary between clients and backend services. Its core functionalities include:
- Request Routing: API Gateway routes incoming API requests to the appropriate backend services, such as Lambda functions, HTTP endpoints, or other AWS services. The routing is configured based on the HTTP method (GET, POST, PUT, DELETE, etc.), the resource path (e.g., /users, /products), and other request parameters.
- Authentication and Authorization: API Gateway supports various authentication and authorization mechanisms to secure APIs. It can validate API keys, use OAuth 2.0, OpenID Connect, or custom authorizers to verify the identity of API callers and control access to resources.
- Request Transformation and Validation: API Gateway can transform incoming requests before they are sent to the backend. This might involve modifying headers, mapping request parameters, or validating request bodies against predefined schemas.
- Response Transformation: API Gateway can also transform responses from backend services before sending them back to the client. This allows for data formatting, filtering, and other modifications to optimize the response for the client.
- Throttling and Rate Limiting: API Gateway provides built-in throttling and rate-limiting capabilities to protect backend services from overload and ensure fair usage. This helps to prevent denial-of-service attacks and maintain the performance of the API.
- Monitoring and Logging: API Gateway integrates with other AWS services like CloudWatch for monitoring API performance and logging API requests and responses. This provides valuable insights into API usage, performance metrics, and potential issues.
Overview of Lambda Functions
Lambda functions are serverless compute services that allow developers to run code without provisioning or managing servers. They execute code in response to events, such as API requests, file uploads, database updates, and more.Lambda functions offer several key benefits:
- Automatic Scaling: Lambda automatically scales the compute resources based on the incoming workload. It handles the scaling, so developers don’t need to worry about managing servers or capacity.
- Pay-per-Use Pricing: Developers are only charged for the compute time consumed by their Lambda functions. This pay-per-use model can significantly reduce costs, especially for applications with fluctuating traffic patterns.
- Event-Driven Architecture: Lambda functions can be triggered by various events, making them ideal for building event-driven architectures. This allows for asynchronous processing and real-time updates.
- Support for Multiple Languages: Lambda supports a wide range of programming languages, including Node.js, Python, Java, Go, and others.
- Simplified Deployment: Lambda functions are easy to deploy and manage. Developers can upload their code and configure the function’s triggers and settings through the AWS Management Console or using infrastructure-as-code tools.
Advantages of Using API Gateway and Lambda Functions Together
The combination of API Gateway and Lambda functions provides several advantages for building RESTful APIs:
- Scalability and High Availability: Both API Gateway and Lambda are designed for scalability and high availability. API Gateway automatically scales to handle incoming traffic, and Lambda functions scale automatically based on the demand.
- Cost-Effectiveness: The pay-per-use pricing model of Lambda, combined with the managed nature of API Gateway, can significantly reduce infrastructure costs, especially for applications with variable traffic patterns.
- Simplified Development and Deployment: Serverless architectures using API Gateway and Lambda simplify development and deployment. Developers can focus on writing business logic without managing servers or infrastructure.
- Improved Security: API Gateway provides built-in security features, such as authentication, authorization, and rate limiting, which help to secure APIs.
- Increased Agility: The flexibility of Lambda functions and the ease of deployment allow for rapid iteration and the ability to quickly adapt to changing business requirements.
- Reduced Operational Overhead: Using a serverless architecture reduces the operational overhead associated with managing servers, such as patching, updates, and monitoring.
Setting up API Gateway
Setting up an API Gateway is a crucial step in deploying RESTful APIs backed by Lambda functions. This process involves configuring the gateway to accept requests, route them to the appropriate Lambda functions, and handle responses. The specifics of this setup vary slightly depending on the cloud provider, but the fundamental principles remain consistent. This section will detail the steps involved in creating and configuring an API Gateway, focusing on the common functionalities needed for a functional REST API.
Creating an API Gateway in a Cloud Provider Environment
The initial step in deploying an API Gateway is to create the gateway resource within the chosen cloud provider’s console or using infrastructure-as-code tools. This typically involves specifying the API’s name, description, and access type (e.g., public or private). The selection of the access type is critical as it determines how the API will be accessed. Public APIs are accessible from the internet, while private APIs are accessible only from within a Virtual Private Cloud (VPC) or through specific configured access mechanisms.The creation process generally follows these steps:
- Access the Cloud Provider’s Console: Navigate to the API Gateway service within the cloud provider’s management console. This service often has a dedicated section for API management.
- Create a New API: Initiate the creation of a new API. This usually involves clicking a “Create API” button or similar.
- Choose an API Type: Select the API type. This may include options like REST, HTTP, or WebSocket APIs. The REST API type is typically chosen for building RESTful APIs with Lambda functions.
- Configure API Details: Provide the API’s name, description, and endpoint configuration (e.g., regional, edge-optimized). The name should be descriptive and reflect the API’s purpose.
- Deploy the API: After configuring the API, it needs to be deployed to a specific stage (e.g., development, staging, production). Deploying creates an accessible endpoint. The deployment process will usually generate a unique URL that can be used to access the API.
Configuring API Gateway Endpoints for Different HTTP Methods
Configuring endpoints for various HTTP methods (GET, POST, PUT, DELETE) is a core aspect of API Gateway setup. Each endpoint maps a specific HTTP method and path to a backend integration, which, in this case, is a Lambda function. This configuration defines how the API Gateway routes incoming requests to the appropriate backend service.The process of configuring these endpoints generally includes:
- Defining the Resource: Create the resource path that represents the API endpoint (e.g., `/users`, `/products/productId`). The resource structure should reflect the API’s logical organization.
- Adding Methods: For each resource, define the HTTP methods that the API will support (e.g., GET, POST, PUT, DELETE). Each method represents a distinct operation on the resource.
- Configuring Integration: Link each method to a backend integration, which is typically a Lambda function. This involves specifying the Lambda function’s ARN (Amazon Resource Name) and any necessary configuration parameters.
- Setting Request and Response Transformations: Define how requests are transformed before being sent to the Lambda function and how responses are transformed before being returned to the client. This may involve mapping request parameters, transforming request bodies, and modifying response payloads.
- Testing the Endpoints: Use the cloud provider’s console or a tool like Postman to test the endpoints. Send requests to the API and verify that the correct Lambda function is invoked and that the response is as expected.
For example, consider a `/products` resource:
- GET `/products`: Retrieves a list of products. This method is integrated with a Lambda function that fetches product data from a database.
- POST `/products`: Creates a new product. This method is integrated with a Lambda function that handles product creation.
- GET `/products/productId`: Retrieves a specific product by its ID. This method is integrated with a Lambda function that fetches a specific product based on the `productId` parameter.
- PUT `/products/productId`: Updates an existing product. This method is integrated with a Lambda function that handles product updates.
- DELETE `/products/productId`: Deletes a product. This method is integrated with a Lambda function that handles product deletion.
Defining Request and Response Models within the API Gateway
Request and response models define the structure and format of data exchanged between the client and the API. Defining these models within the API Gateway provides several benefits, including input validation, response transformation, and improved API documentation. This ensures data consistency and simplifies API usage.Defining request and response models generally involves:
- Creating Models: Define models for both requests and responses using formats like JSON Schema. These models specify the expected data types, required fields, and other constraints.
- Associating Models with Methods: Associate the models with specific API methods. For example, the POST `/products` method might be associated with a request model that defines the structure of the product data to be sent in the request body. The response model would define the structure of the product data returned in the response.
- Enabling Validation: Configure the API Gateway to validate incoming requests against the defined request models. If a request does not conform to the model, the API Gateway can reject it and return an error.
- Transforming Data: Use the models to transform data between the client and the backend. This might involve mapping request parameters to the Lambda function’s input or transforming the Lambda function’s response to match the expected response model.
For instance, a request model for creating a product (POST `/products`) might define the following JSON schema:
"type": "object", "properties": "name": "type": "string" , "description": "type": "string" , "price": "type": "number" , "required": [ "name", "price" ]
This model specifies that the request body must be a JSON object with `name`, `description`, and `price` properties.
The `name` and `description` must be strings, and the `price` must be a number. The `name` and `price` fields are required. The API Gateway would validate incoming requests against this schema, ensuring that the data is in the correct format before forwarding it to the Lambda function. The response model would define the format of the response returned to the client, which could be a JSON object containing the created product’s details.
This approach ensures data consistency and facilitates robust API design.
Creating Lambda Functions for RESTful APIs
This section focuses on the practical implementation of Lambda functions designed to handle RESTful API requests. We will examine the creation and deployment of these functions, specifically addressing GET and POST methods. The objective is to demonstrate the core functionalities, including response formatting and input validation, within the context of a cloud environment.
Creating a Python Lambda Function for GET Requests
A Python Lambda function can be crafted to process GET requests and deliver a JSON response. This example illustrates the basic structure and functionality required for such an implementation. The primary focus is on data retrieval and response formatting suitable for API consumption.
- Function Definition: The core of the function involves defining a handler that receives an event object (containing request data) and a context object. The handler’s primary role is to process the incoming event and construct a response.
- Data Retrieval: In a real-world scenario, the function would likely interact with a database or other data sources to retrieve the necessary information. For this example, a static JSON response is used to simplify the illustration.
- JSON Response Formatting: The response must be formatted as JSON to be compatible with RESTful API standards. The function uses the `json.dumps()` method to convert a Python dictionary into a JSON string.
- HTTP Status Code: The response includes an HTTP status code, typically 200 OK for successful GET requests. This is essential for the API client to interpret the result of the request.
“`python
import json
def lambda_handler(event, context):
“””
This function handles GET requests and returns a JSON response.
“””
response =
“statusCode”: 200,
“headers”:
“Content-Type”: “application/json”
,
“body”: json.dumps(
“message”: “Hello from GET request!”,
“data”:
“key1”: “value1”,
“key2”: “value2”
)
return response
“`
This Python code defines a simple Lambda function that returns a JSON response when triggered by a GET request. The function includes a `statusCode` of 200 (OK) and a `Content-Type` header indicating JSON. The `body` contains a JSON-formatted string with a greeting message and sample data.
Organizing a Node.js Lambda Function for POST Requests
Node.js Lambda functions are commonly employed to manage POST requests, which often involve data submission and processing. This section Artikels how to structure such a function, including critical aspects like input validation. Input validation is crucial for data integrity and security.
- Input Validation: Validating the input data is paramount to ensure the integrity and security of the application. This involves checking the data type, format, and required fields of the submitted data.
- Request Body Parsing: The function must parse the request body, which typically contains the data sent in the POST request. The `event.body` property provides access to the request body.
- Response Handling: The function constructs a response that includes an HTTP status code and a JSON-formatted body, which provides feedback to the client regarding the success or failure of the request.
“`javascript
exports.handler = async (event) =>
try
// Parse the request body
const requestBody = JSON.parse(event.body);
// Input Validation
if (!requestBody.name || typeof requestBody.name !== ‘string’)
return
statusCode: 400,
body: JSON.stringify( message: ‘Invalid input: name is required and must be a string.’ )
;
if (!requestBody.email || !/^[^\s@]+@[^\s@]+\.[^\s@]+$/.test(requestBody.email))
return
statusCode: 400,
body: JSON.stringify( message: ‘Invalid input: email is required and must be a valid email address.’ )
;
// Process the data (example: save to database)
const responseData =
message: `Successfully processed data for $requestBody.name`,
data:
name: requestBody.name,
email: requestBody.email
;
const response =
statusCode: 200,
headers:
‘Content-Type’: ‘application/json’
,
body: JSON.stringify(responseData)
;
return response;
catch (error)
console.error(‘Error:’, error);
return
statusCode: 500,
body: JSON.stringify( message: ‘Internal server error’ )
;
;
“`
This Node.js code defines a Lambda function to handle POST requests. The function first parses the request body, validates the input data (name and email), and then processes the data (simulated). If validation fails, it returns a 400 Bad Request status with an error message. On success, it returns a 200 OK status with a confirmation message and the processed data.
Error handling includes a catch block to manage potential errors, returning a 500 Internal Server Error.
Demonstrating Deployment of Lambda Functions
Deploying Lambda functions involves uploading the code and configuring the necessary settings within your cloud provider’s console or through infrastructure-as-code tools. The deployment process varies slightly depending on the cloud provider, but the core steps remain consistent.
- Packaging the Code: The function code, along with any dependencies, needs to be packaged. For Python, this often involves creating a ZIP file containing the `.py` file and any required libraries. For Node.js, the `node_modules` directory and the function file are typically included.
- Creating the Lambda Function: Within the cloud provider’s console (e.g., AWS Lambda), you create a new function, specifying the runtime (Python or Node.js), the function name, and the execution role (which defines the permissions the function has).
- Uploading the Code: The packaged code is uploaded to the Lambda function. This can be done through the console or using the cloud provider’s CLI or SDK.
- Configuring the Trigger (API Gateway): The Lambda function needs to be integrated with API Gateway. This involves creating an API Gateway endpoint and configuring it to trigger the Lambda function. This step establishes the connection between the API endpoint and the function.
- Testing the Function: After deployment, you can test the function using the API Gateway endpoint. This involves sending requests to the endpoint and verifying the response from the Lambda function.
Deployment processes often integrate with CI/CD pipelines, streamlining the process of updating and managing Lambda functions. Automated deployments ensure that changes are quickly and efficiently propagated to the production environment. Cloud providers also offer monitoring and logging tools to observe the function’s performance and identify any issues.
Integrating API Gateway with Lambda Functions
The integration of API Gateway with Lambda functions is the cornerstone of building serverless RESTful APIs. This process facilitates the execution of code in response to API requests, enabling dynamic and scalable backend logic. Properly configuring this integration is crucial for handling incoming requests, processing data, and returning appropriate responses. This section details the steps involved in connecting API Gateway endpoints to Lambda functions, mapping request parameters, and configuring content type handling.
Connecting API Gateway Endpoints to Lambda Functions
Connecting API Gateway endpoints to Lambda functions involves configuring API Gateway to route incoming requests to the appropriate Lambda function. This is achieved through the API Gateway console or Infrastructure as Code (IaC) tools.
The process involves several key steps:
- Creating an API Gateway Resource: Within API Gateway, a resource (e.g., `/users`, `/products`) represents a logical endpoint in the API. This resource acts as a container for methods (e.g., `GET`, `POST`, `PUT`, `DELETE`).
- Creating an API Gateway Method: For each HTTP method (e.g., `GET`, `POST`) supported by the resource, a method must be created. This defines the request and response behavior for that method.
- Configuring the Integration Type: The integration type is set to “Lambda Function”. This specifies that the method will be integrated with a Lambda function.
- Specifying the Lambda Function: The Lambda function to be invoked is selected by specifying its name or ARN (Amazon Resource Name).
- Setting the Integration Request: This step configures how the API Gateway method will pass the request to the Lambda function. This includes mapping request parameters, headers, and the request body.
- Setting the Integration Response: This step defines how the Lambda function’s response will be transformed and passed back to the client. This involves mapping the Lambda function’s output to HTTP status codes and defining response headers and the response body.
- Testing the Integration: After configuring the integration, it’s crucial to test it through the API Gateway console or a tool like Postman to verify that requests are correctly routed to the Lambda function and responses are received as expected.
For example, when a user makes a `GET` request to `/users` through the API Gateway, the Gateway will route the request to the associated Lambda function. The Lambda function will then execute, process the request (e.g., retrieve user data from a database), and return a response to the API Gateway. The API Gateway then transforms the Lambda function’s response into a format understood by the client.
Mapping API Gateway Request Parameters to Lambda Function Inputs
Mapping request parameters is a critical component of API Gateway and Lambda function integration, allowing data from client requests to be passed to the Lambda function for processing. This mapping process enables the Lambda function to receive and utilize data such as query parameters, path parameters, headers, and the request body.
The mapping process typically involves these key steps:
- Identifying Request Parameters: API Gateway identifies various types of request parameters:
- Path Parameters: Values within the URL path (e.g., `/users/userId`).
- Query Parameters: Key-value pairs appended to the URL (e.g., `?limit=10&offset=0`).
- Headers: HTTP headers sent with the request (e.g., `Content-Type`, `Authorization`).
- Request Body: The data sent in the request body, often in JSON or XML format.
- Setting up the Integration Request: In the API Gateway console, within the method’s Integration Request section, mapping templates and request parameters can be configured.
- Mapping Templates: Mapping templates are used to transform the incoming request data into a format that the Lambda function can easily consume. The `application/json` content type is frequently used. For example, a mapping template could extract specific fields from the request body.
- Parameter Mapping: API Gateway can map request parameters (query parameters, path parameters, and headers) to the Lambda function’s input. This is often done by specifying the “Method request parameters” and mapping them to the “Integration request parameters.”
- Accessing Parameters in the Lambda Function: The Lambda function receives the mapped parameters in the event object. The event object structure depends on the integration configuration. The Lambda function can then access these parameters and use them for its logic.
For instance, if an API endpoint `/products/productId` receives a `GET` request, the `productId` is a path parameter. The Lambda function would access this `productId` from the `event` object provided by API Gateway. The Lambda function then utilizes the product ID to fetch product details from a database.
Configuring API Gateway to Handle Different Content Types
API Gateway must be configured to handle various content types (e.g., JSON, XML) to support different client applications. This configuration ensures that API Gateway can correctly parse and forward requests, and transform responses in the appropriate format.
The process involves several key considerations:
- Request Content Type: API Gateway uses the `Content-Type` header in the request to determine the content type. The `Content-Type` header indicates the format of the data being sent in the request body (e.g., `application/json`, `application/xml`).
- Request Body Mapping Templates: API Gateway uses mapping templates to transform the request body into a format that the Lambda function can understand. These templates are defined for specific content types. For example:
- JSON: For `application/json`, a mapping template might transform the request body into a JSON object.
- XML: For `application/xml`, a mapping template might transform the request body into an XML object, or convert it to JSON.
- Response Content Type: The Lambda function’s response should include the `Content-Type` header to indicate the content type of the response body. API Gateway uses this header to determine how to format the response.
- Response Body Mapping Templates: API Gateway can also use mapping templates to transform the Lambda function’s response body before sending it back to the client. This can be used to format the response in a specific way.
- Content Negotiation: API Gateway can be configured to perform content negotiation, where it selects the best response format based on the client’s `Accept` header. This allows the API to serve different content types to different clients.
For example, when an API endpoint receives a `POST` request with `Content-Type: application/json`, API Gateway uses the `application/json` mapping template to parse the JSON data. The Lambda function receives the parsed JSON data in the event object. The Lambda function then processes the data and returns a JSON response. API Gateway will then pass the JSON response back to the client.
If the Lambda function returns an XML response, the response would be formatted accordingly.
Handling Request and Response with Lambda Functions
Effectively managing requests and crafting appropriate responses are critical components of a RESTful API. Lambda functions, when integrated with API Gateway, act as the processing units, receiving requests, executing logic, and returning results. This section details the methods for parsing request bodies, handling HTTP status codes, and formatting responses to ensure seamless interaction between API Gateway and Lambda functions.
Parsing and Processing Request Bodies
Understanding how to extract and interpret data from request bodies is fundamental for any Lambda function designed to handle POST, PUT, or PATCH requests. The request body, typically containing JSON data, must be parsed to access the information needed for processing.
To parse a request body, the Lambda function needs to access the `event` object provided by API Gateway. This object contains all the information about the incoming request, including the body. The `event.body` attribute will contain the raw request body as a string. This string then needs to be parsed into a usable format, such as a JavaScript object, using a JSON parser.
Here’s an example using JavaScript:
“`javascript
exports.handler = async (event) =>
try
const requestBody = JSON.parse(event.body);
// Accessing specific data from the request body
const name = requestBody.name;
const age = requestBody.age;
// Perform operations with the extracted data
const message = `Hello, $name! You are $age years old.`;
return
statusCode: 200,
body: JSON.stringify( message: message ),
;
catch (error)
console.error(‘Error parsing JSON:’, error);
return
statusCode: 400,
body: JSON.stringify( error: ‘Invalid JSON format’ ),
;
;
“`
In this example:
- The `event.body` is accessed.
- `JSON.parse()` is used to convert the string into a JavaScript object.
- Specific properties (`name`, `age`) are accessed from the parsed object.
- The function then uses these properties to generate a response.
The `try…catch` block is crucial for error handling, specifically for situations where the request body is not valid JSON. If an error occurs during parsing, the `catch` block provides a mechanism to return a 400 Bad Request status code, indicating a problem with the client’s request.
Handling HTTP Status Codes
HTTP status codes are a critical element in RESTful APIs, communicating the outcome of a request to the client. Lambda functions, through their response format, control these status codes, allowing for precise feedback on the request’s success or failure. Correctly setting these codes is essential for API functionality.
The following examples illustrate how to handle different HTTP status codes:
- 200 OK: This status code indicates that the request was successful. The Lambda function should return this code when the request is processed without any errors. The response body should typically contain the data requested or the result of a successful operation.
- 400 Bad Request: This code signals that the server cannot or will not process the request due to something that is perceived to be a client error. This can be due to invalid data, missing required parameters, or incorrect formatting in the request body.
- 500 Internal Server Error: This code indicates that the server encountered an unexpected condition that prevented it from fulfilling the request. This often points to an issue on the server side, such as an unhandled exception in the Lambda function or a problem with a dependent service.
Here are some code examples to demonstrate:
200 OK (Success):
“`javascript
exports.handler = async (event) =>
try
// Successful operation
const data = message: “Operation completed successfully” ;
return
statusCode: 200,
body: JSON.stringify(data),
;
catch (error)
// Handle errors
;
“`
400 Bad Request (Client Error):
“`javascript
exports.handler = async (event) =>
try
const requestBody = JSON.parse(event.body);
if (!requestBody.name || requestBody.name.length === 0)
return
statusCode: 400,
body: JSON.stringify( error: “Name is required” ),
;
// Proceed with processing if the name is provided
catch (error)
return
statusCode: 400,
body: JSON.stringify( error: “Invalid JSON format” ),
;
;
“`
500 Internal Server Error (Server Error):
“`javascript
exports.handler = async (event) =>
try
// Simulate an error condition (e.g., database connection failure)
throw new Error(“Simulated server error”);
catch (error)
console.error(“Error:”, error);
return
statusCode: 500,
body: JSON.stringify( error: “Internal server error” ),
;
;
“`
These examples illustrate the importance of error handling and providing informative responses to the client.
Format of the Lambda Function’s Response
The Lambda function’s response format must adhere to a specific structure for API Gateway to correctly interpret it. This structure includes the HTTP status code, headers, and the body of the response. The response should be formatted as a JavaScript object.
The essential components of the response object are:
- `statusCode`: An integer representing the HTTP status code (e.g., 200, 400, 500).
- `headers`: An optional object containing HTTP response headers. This is critical for setting `Content-Type`, `Access-Control-Allow-Origin`, and other relevant headers.
- `body`: A string containing the response body. The body should be serialized JSON.
The `body` must be a string. Therefore, any data returned from the Lambda function needs to be converted into a JSON string using `JSON.stringify()`. This ensures the data is in a format that API Gateway can understand and pass back to the client.
Here’s a comprehensive example demonstrating the response format:
“`javascript
exports.handler = async (event) =>
try
const requestBody = JSON.parse(event.body);
const name = requestBody.name;
const message = `Hello, $name!`;
const response =
statusCode: 200,
headers:
‘Content-Type’: ‘application/json’,
‘Access-Control-Allow-Origin’: ‘*’ // Required for CORS if API Gateway is configured for it
,
body: JSON.stringify( message: message )
;
return response;
catch (error)
console.error(‘Error:’, error);
const response =
statusCode: 400,
headers:
‘Content-Type’: ‘application/json’
,
body: JSON.stringify( error: ‘Bad Request’ )
;
return response;
;
“`
In this example:
- The `statusCode` is set to 200 for a successful response.
- The `headers` object includes the `Content-Type` header, indicating that the response body is in JSON format. It also includes the `Access-Control-Allow-Origin` header to allow cross-origin requests, a common requirement for web applications.
- The `body` contains the serialized JSON data.
Properly formatting the response ensures that API Gateway can correctly interpret the Lambda function’s output and deliver the data to the client in a usable format.
Authentication and Authorization
Securing RESTful APIs is paramount for protecting sensitive data and ensuring only authorized users can access resources. Authentication verifies the identity of a user, while authorization determines their access rights. API Gateway provides various mechanisms to implement both, enhancing the security posture of your API endpoints.
Authentication Methods Using API Gateway
API Gateway offers several authentication methods, each with its own strengths and weaknesses, catering to different security requirements. Choosing the right method depends on the application’s needs and the trade-offs between security, usability, and complexity.
- API Keys: This method uses a unique key associated with an API. Clients must provide this key in their requests to access the API. API keys are simple to implement and useful for rate limiting and usage tracking. They are suitable for scenarios where client identification is needed but strict user authentication isn’t necessary. However, API keys alone don’t verify the user’s identity.
- IAM Roles: API Gateway can integrate with AWS Identity and Access Management (IAM) to authenticate requests using IAM roles and policies. This is particularly useful for authorizing requests from other AWS services. The requesting service assumes an IAM role, and the API Gateway verifies the role’s permissions. This method offers fine-grained access control and is ideal for internal API usage within the AWS ecosystem.
- AWS Lambda Authorizers: Lambda authorizers are custom functions that API Gateway invokes to authenticate and authorize requests. These functions can implement various authentication schemes, including OAuth 2.0, JWT validation, and custom authentication logic. Lambda authorizers offer maximum flexibility and control, allowing developers to integrate with existing authentication systems.
- Amazon Cognito User Pools: API Gateway can integrate with Amazon Cognito user pools to handle user sign-up, sign-in, and token management. Cognito provides a fully managed user directory and authentication service. This is a good option for applications that require user management features, such as password reset and multi-factor authentication (MFA). Cognito also integrates well with other AWS services.
- JSON Web Token (JWT): JWT is a widely used standard for representing claims securely between two parties. API Gateway can validate JWTs using built-in mechanisms or through Lambda authorizers. The token typically contains user identity information and permissions. This method is suitable for stateless authentication and works well in microservices architectures. The JWT is signed, ensuring its integrity.
Designing an Authorization System
An effective authorization system ensures that users can only access resources they are permitted to access. This involves defining user roles, assigning permissions to those roles, and enforcing these permissions at the API Gateway level.
- Defining User Roles: Start by defining the roles within your application. These roles represent different levels of access and responsibilities. Examples include “administrator,” “editor,” and “viewer.” The roles should align with the functional requirements of your API.
- Assigning Permissions to Roles: Determine the specific permissions each role requires. Permissions define what actions a user with a particular role can perform on specific resources. For example, an “administrator” might have permission to “create,” “read,” “update,” and “delete” all resources, while an “editor” might only have “read” and “update” permissions on certain resources.
- Implementing Authorization Logic: The authorization logic is typically implemented in a Lambda function or within the API Gateway configuration. This logic examines the user’s identity (obtained through authentication) and their assigned roles. It then checks if the user has the necessary permissions to access the requested resource or perform the requested action.
- Enforcing Authorization at the API Gateway: API Gateway can be configured to enforce authorization policies. This can be done using IAM policies, custom authorizers, or built-in features. The API Gateway intercepts the request and checks the user’s permissions before forwarding the request to the backend Lambda function.
Securing API Endpoints
Securing API endpoints involves a combination of authentication, authorization, and other security best practices. Implementing these measures protects the API from various threats, including unauthorized access, data breaches, and denial-of-service attacks.
- HTTPS Encryption: Always use HTTPS to encrypt all communication between the client and the API Gateway. This protects sensitive data in transit from eavesdropping and tampering.
- Input Validation: Validate all incoming data to prevent injection attacks, such as SQL injection and cross-site scripting (XSS). Implement strict input validation rules to ensure that the data conforms to the expected format and type.
- Rate Limiting: Implement rate limiting to protect the API from abuse and denial-of-service (DoS) attacks. API Gateway provides built-in rate limiting capabilities. Configure these to limit the number of requests a client can make within a specific time window.
- API Key Management: If using API keys, manage them securely. Regularly rotate API keys, and avoid embedding them directly in client-side code. Consider using environment variables or a secrets management service.
- JWT Best Practices: If using JWTs, implement best practices such as setting short expiration times, using strong signing algorithms (e.g., HMAC-SHA256 or RSA-SHA256), and validating the “aud” (audience) and “iss” (issuer) claims in the token.
- Least Privilege Principle: Grant users and services only the minimum necessary permissions. Avoid assigning overly broad permissions. This minimizes the impact of a potential security breach.
- Regular Security Audits: Conduct regular security audits and penetration testing to identify and address vulnerabilities. Review your API configuration, code, and infrastructure regularly.
- Web Application Firewall (WAF): Consider using a Web Application Firewall (WAF) to protect against common web attacks, such as SQL injection, cross-site scripting, and bot attacks.
- Logging and Monitoring: Implement comprehensive logging and monitoring to track API usage, detect suspicious activity, and troubleshoot issues. Monitor API metrics such as error rates, latency, and traffic volume.
Request Validation and Error Handling

Effective request validation and robust error handling are critical components of a well-designed RESTful API. These practices ensure data integrity, enhance API security, and provide a positive user experience by delivering clear and actionable feedback to API consumers. Implementing these strategies within the API Gateway and Lambda function framework contributes to a resilient and maintainable system.
Validating Incoming Request Data in API Gateway
API Gateway provides mechanisms to validate incoming requests before they reach the Lambda functions. This pre-processing step reduces the load on the Lambda functions and prevents them from processing invalid data, thus optimizing performance and reducing potential errors.
API Gateway offers several methods for request validation:
- Request Schema Validation: API Gateway allows defining request schemas using JSON Schema. These schemas specify the expected structure and data types of the request payload, headers, and query parameters. When a request is received, API Gateway validates it against the defined schema. If the request fails validation, API Gateway rejects the request and returns an error to the client. This is the most comprehensive form of validation.
- Method Request Parameters: Within the API Gateway console, you can configure the required and optional parameters for your API methods (e.g., path parameters, query string parameters, and request headers). You can specify whether a parameter is required, and API Gateway will validate the presence of these parameters in the incoming request.
- Request Body Validation: If the request includes a body (e.g., in a POST or PUT request), API Gateway can validate the content type and, using integration with schemas, the content itself. This is particularly useful for ensuring the format and data integrity of JSON payloads.
To illustrate, consider a POST request to create a new user. The request body might be expected to contain a JSON payload with fields like `name` (string), `email` (string), and `age` (integer). Using JSON Schema within API Gateway, we can define a schema that specifies these requirements. For example:
“`json
“type”: “object”,
“properties”:
“name”: “type”: “string”, “minLength”: 2 ,
“email”: “type”: “string”, “format”: “email” ,
“age”: “type”: “integer”, “minimum”: 0
,
“required”: [“name”, “email”, “age”]
“`
If a request is received without the `name` field or with an invalid email address, API Gateway will reject it based on this schema. The rejection provides a clear error message, guiding the client to correct the request.
Best Practices for Handling Errors in Lambda Functions
Effective error handling within Lambda functions is essential for building resilient and maintainable APIs. Well-defined error handling enables the function to gracefully manage unexpected situations, preventing application crashes and providing useful information for debugging and monitoring.
Key best practices include:
- Specific Exception Handling: Use `try-except` blocks to catch specific exceptions, such as `ValueError`, `TypeError`, or custom exceptions. This allows you to handle different error scenarios with tailored responses.
- Logging: Implement robust logging to capture detailed information about errors, including stack traces, input parameters, and timestamps. Utilize logging libraries to structure and format logs for easier analysis. CloudWatch is commonly used for Lambda function logging.
- Custom Error Classes: Define custom exception classes to represent specific error conditions relevant to your API’s domain. This improves code readability and allows for more precise error handling.
- Error Propagation: Propagate relevant error information back to the API Gateway. This involves creating custom error responses with appropriate HTTP status codes and informative error messages.
- Monitoring and Alerting: Set up monitoring and alerting on error rates, error types, and other relevant metrics. This allows you to proactively identify and address issues in your API.
Consider a Lambda function designed to retrieve data from a database. If the database connection fails, the function should catch the exception, log the error, and return an appropriate HTTP status code (e.g., 500 Internal Server Error) along with an informative error message in the response body. For instance, if using Python, you might structure error handling as follows:
“`python
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
try:
# Simulate database connection failure
raise Exception(“Simulated database connection error”)
# … (database interaction code) …
data = “message”: “Data retrieved successfully”
return
“statusCode”: 200,
“body”: json.dumps(data)
except Exception as e:
logger.error(f”An error occurred: str(e)”)
return
“statusCode”: 500,
“body”: json.dumps(“message”: “Internal Server Error: Failed to retrieve data.”)
“`
In this example, the function catches any exception, logs the error, and returns a 500 error with a generic error message. More sophisticated implementations would catch specific exception types (e.g., `DatabaseConnectionError`) and return more specific error messages.
Returning Informative Error Messages to the API Consumer
The design of error responses significantly impacts the user experience. Providing clear, concise, and actionable error messages allows API consumers to quickly understand and resolve issues, leading to greater satisfaction and reduced support requests.
Key elements of informative error messages include:
- HTTP Status Codes: Use appropriate HTTP status codes to indicate the nature of the error (e.g., 400 Bad Request for client-side errors, 500 Internal Server Error for server-side errors).
- Error Codes: Include specific error codes to categorize different error scenarios. This allows clients to programmatically handle different error types.
- Error Messages: Provide clear and concise error messages that describe the problem. Avoid generic messages like “Internal Server Error.” Instead, be specific, such as “Invalid email address format” or “Resource not found.”
- Error Details: Include additional details, such as the field that caused the error (for validation errors) or the specific reason for the failure (for database errors). Be cautious about exposing sensitive information.
- Error Structure (JSON): Structure error responses in a consistent JSON format for easy parsing by clients.
A typical error response might follow this structure:
“`json
“error”:
“code”: “INVALID_EMAIL”,
“message”: “The email address is not valid.”,
“details”:
“field”: “email”,
“value”: “invalid-email”
“`
This format provides the client with an error code for programmatic handling, a user-friendly message, and specific details about the cause of the error.
In the API Gateway configuration, you can map Lambda function errors to specific HTTP status codes and response bodies. This allows you to control the error responses returned to the API consumer. For instance, if a Lambda function returns a custom error object, API Gateway can be configured to map that object to a 400 Bad Request response with a specific JSON payload.
This ensures that the API consumer receives a consistent and informative error response, enhancing the usability and reliability of the API.
Deployment and Versioning
Deploying API Gateway and Lambda functions to a production environment requires careful consideration of various factors, including security, scalability, and maintainability. Effective versioning and deployment strategies are crucial for minimizing downtime, enabling rollback capabilities, and ensuring a smooth user experience. The following sections detail the process of deploying and versioning APIs built with API Gateway and Lambda functions.
Deploying to Production
Deploying an API to production involves several key steps to ensure its stability, security, and availability. This includes setting up the appropriate infrastructure, configuring security measures, and thoroughly testing the API before making it publicly accessible.
- Infrastructure Setup: The initial step involves configuring the necessary infrastructure to support the API. This includes defining the AWS resources like API Gateway, Lambda functions, and any required supporting services such as databases (e.g., Amazon DynamoDB, Amazon RDS) or message queues (e.g., Amazon SQS). The infrastructure should be provisioned using Infrastructure as Code (IaC) tools such as AWS CloudFormation, Terraform, or the AWS CDK.
IaC allows for consistent and repeatable deployments, making it easier to manage and scale the infrastructure. For example, a CloudFormation template might define an API Gateway API, Lambda functions, IAM roles with the necessary permissions, and any associated VPC configurations if the Lambda functions need access to resources within a private network.
- Security Configuration: Security is paramount in a production environment. Implement appropriate security measures such as:
- API Keys: Utilize API keys to control access to the API and monitor usage. This helps to prevent unauthorized access and can be used for rate limiting.
- Authentication and Authorization: Integrate authentication mechanisms (e.g., OAuth 2.0, JSON Web Tokens (JWTs)) to verify user identities. Implement authorization rules to restrict access to specific resources based on user roles or permissions.
- Input Validation: Validate all incoming requests to prevent vulnerabilities such as injection attacks. This includes validating the request body, headers, and query parameters.
- Encryption: Encrypt sensitive data at rest and in transit using HTTPS.
- Testing and Validation: Thoroughly test the API before deploying it to production. This includes:
- Unit Tests: Test individual Lambda functions to ensure they function correctly.
- Integration Tests: Test the interaction between Lambda functions and other services, such as databases.
- End-to-End Tests: Test the entire API flow, from the client request to the Lambda function response.
- Performance Testing: Evaluate the API’s performance under load to ensure it can handle the expected traffic. Tools like JMeter or AWS Load Balancer can be used for this purpose.
- Security Testing: Conduct security testing, including penetration testing and vulnerability scanning, to identify and address potential security flaws.
- Deployment Process: Automate the deployment process to ensure consistency and reduce the risk of errors. This often involves using CI/CD pipelines.
- CI/CD Pipelines: Implement a CI/CD pipeline using tools like AWS CodePipeline, Jenkins, or GitLab CI/CD. The pipeline should automate the build, test, and deployment processes.
- Blue/Green Deployments: Use blue/green deployments to minimize downtime during updates. This involves deploying the new version of the API to a “green” environment and then switching traffic over from the existing “blue” environment.
- Rollback Strategy: Define a rollback strategy in case of deployment failures. This should include the ability to quickly revert to the previous working version of the API.
- Monitoring and Logging: Implement comprehensive monitoring and logging to track the API’s performance and identify issues.
- CloudWatch Metrics: Utilize Amazon CloudWatch to monitor API Gateway metrics such as request count, latency, and error rates.
- CloudWatch Logs: Enable logging for API Gateway and Lambda functions to capture detailed information about requests and responses.
- Alerting: Set up alerts in CloudWatch to be notified of any issues or performance degradations.
Implementing API Versioning Strategies
API versioning is critical for managing changes to an API over time. Without versioning, changes to the API could break existing clients. Several strategies exist for implementing API versioning, each with its own advantages and disadvantages.
- URI Versioning: In URI versioning, the version number is included in the API’s URL. For example:
/v1/users/v2/users
This approach is straightforward and easy to understand. It clearly separates different versions of the API. However, it can lead to a proliferation of endpoints as the API evolves. Each version of the API becomes a distinct endpoint.
- Header Versioning: In header versioning, the version number is specified in a custom header in the HTTP request. For example:
Accept: application/vnd.example.v1+jsonAccept: application/vnd.example.v2+json
This approach is more flexible than URI versioning and allows for more seamless upgrades. It doesn’t require changes to the URL, so clients can continue to use the same endpoint. However, it relies on clients to correctly specify the version header.
- Query Parameter Versioning: In query parameter versioning, the version number is included as a query parameter in the URL. For example:
/users?version=1/users?version=2
This approach is easy to implement and understand. However, it can make URLs less readable and can be less effective for caching.
- Versioning in API Gateway: API Gateway provides built-in support for versioning. You can create multiple API Gateway stages, each representing a different version of your API. This allows you to deploy different versions of your API simultaneously and manage traffic routing between them. For example, you might have a “v1” stage and a “v2” stage, each pointing to different Lambda functions.
Updating Without Downtime
Updating an API without downtime requires a well-defined deployment strategy that minimizes disruption to users. Several techniques can be employed to achieve this.
- Blue/Green Deployments: This is a common strategy for minimizing downtime. The process involves the following steps:
- Create a Green Environment: Deploy the new version of the API to a “green” environment, separate from the existing “blue” environment. This could involve deploying new Lambda functions and configuring a new API Gateway stage.
- Test the Green Environment: Thoroughly test the new version of the API in the green environment to ensure it functions correctly.
- Switch Traffic: Once testing is complete, switch traffic from the blue environment to the green environment. This can be done by updating the API Gateway stage alias or by using a load balancer to gradually shift traffic.
- Monitor the Green Environment: Monitor the performance of the green environment after the traffic switch. If any issues are detected, quickly switch traffic back to the blue environment.
- Decommission the Blue Environment: After a period of stability, decommission the blue environment.
This strategy minimizes downtime by allowing users to continue using the existing version of the API while the new version is being deployed and tested.
- Canary Deployments: This is a more advanced deployment strategy that involves gradually rolling out the new version of the API to a small subset of users (the “canary” users) before rolling it out to everyone. This allows you to detect and address any issues with the new version before they affect all users.
- Deploy to Canary: Deploy the new version of the API to a small percentage of traffic, e.g., 1% or 5%.
- Monitor Canary: Monitor the performance and behavior of the new version with the canary traffic.
- Gradual Rollout: If the canary deployment is successful, gradually increase the percentage of traffic to the new version.
- Full Rollout: Once the new version has been tested and proven stable, roll it out to all users.
- Rollback Capability: If issues arise during the rollout, rollback to the previous version immediately.
Canary deployments provide a more controlled way to release new versions of an API and minimize the risk of breaking changes.
- Rolling Updates: In a rolling update, the new version of the API is deployed to a subset of the infrastructure while the existing version continues to serve traffic. This is a gradual process where the old version is slowly replaced with the new version. This approach can be used with Lambda functions by updating the function code in batches. The API Gateway can then be configured to route traffic to the updated functions.
- Using API Gateway Stages: API Gateway stages provide a mechanism for managing different versions of your API. You can create multiple stages, such as “dev”, “staging”, and “prod”, each pointing to a different version of your Lambda functions. You can then use these stages to control traffic routing and manage deployments.
- Rollback Strategy: Always have a well-defined rollback strategy in place. This should include the ability to quickly revert to the previous working version of the API if any issues are detected during or after deployment. This might involve restoring the previous version of the Lambda functions or reverting the API Gateway configuration.
Monitoring and Logging
Effective monitoring and logging are crucial for maintaining the health, performance, and security of RESTful APIs built with API Gateway and Lambda functions. They provide insights into API behavior, identify potential issues, and facilitate efficient troubleshooting. Proper implementation allows for proactive identification of performance bottlenecks, error trends, and security vulnerabilities, ensuring a reliable and scalable API service.
API Gateway Performance Metrics
API Gateway provides a comprehensive set of metrics that offer insights into its performance. Understanding these metrics is vital for identifying and addressing performance issues, optimizing resource allocation, and ensuring a positive user experience.
- Latency: This metric measures the time taken for API Gateway to process a request, from receiving it to sending a response. It’s a critical indicator of API responsiveness. High latency can signal issues such as slow backend processing, network congestion, or inefficient API Gateway configuration. Monitoring latency allows for the identification of performance degradation over time.
- Error Rates: These metrics quantify the percentage of requests that result in errors. API Gateway tracks various error codes, including 4xx (client errors) and 5xx (server errors). A high error rate indicates problems such as incorrect request formatting, authentication failures, or issues within the Lambda functions. Monitoring error rates helps in pinpointing the source of failures and their impact on API availability.
- Throttle: This metric tracks the number of requests that are throttled due to exceeding the configured limits. Throttling prevents a single user or application from consuming excessive resources, protecting the API from overload. Monitoring throttle metrics helps in determining if API rate limits need adjustment to accommodate legitimate traffic or if there are potential denial-of-service (DoS) attacks.
- Cache Hits/Misses: When API caching is enabled, these metrics indicate the effectiveness of the caching strategy. Cache hits represent requests served directly from the cache, while cache misses require the API Gateway to forward the request to the backend. A low cache hit rate suggests that the caching configuration might not be optimal, potentially leading to increased latency and backend load.
- Integration Latency: This metric measures the time API Gateway spends interacting with the backend (Lambda functions in this context). High integration latency indicates potential issues with the Lambda function’s performance, such as slow database queries, inefficient code, or network latency between API Gateway and the Lambda function.
Setting up Logging for API Gateway and Lambda Functions
Proper logging is essential for debugging, performance analysis, and security auditing. API Gateway and Lambda functions offer built-in logging capabilities that, when configured correctly, provide a detailed record of API requests, responses, and errors.
- API Gateway Logging: API Gateway logging can be configured to record detailed information about each API request, including request and response headers, body, and execution time. This is typically enabled through the API Gateway console or using infrastructure-as-code tools like AWS CloudFormation or Terraform. The logs are stored in Amazon CloudWatch Logs.
- Lambda Function Logging: Lambda functions can use standard logging libraries (e.g., `console.log` in Node.js, `logging` module in Python) to write log messages to CloudWatch Logs. These logs can include custom messages, error details, and performance metrics. Structured logging, using formats like JSON, is highly recommended for easier analysis.
- Log Levels: Implement different log levels (e.g., DEBUG, INFO, WARNING, ERROR) to control the verbosity of logs. This allows for filtering logs based on the severity of the events, simplifying the process of identifying and troubleshooting issues.
- Access Logs vs. Execution Logs: API Gateway access logs provide a high-level view of API traffic, while Lambda execution logs offer detailed information about the function’s behavior. Both are essential for comprehensive monitoring.
- Centralized Logging: Integrate logging with a centralized logging service (e.g., AWS CloudWatch Logs Insights, Elasticsearch, Splunk) to aggregate and analyze logs from multiple sources. This provides a unified view of API performance and allows for correlation of events across different components.
Analyzing Logs for Debugging and Performance Optimization
Analyzing logs is crucial for identifying the root causes of issues, optimizing API performance, and improving security. The analysis process involves several steps, including log aggregation, filtering, and pattern recognition.
- Log Aggregation: Aggregate logs from API Gateway and Lambda functions into a central location (e.g., CloudWatch Logs, Elasticsearch). This enables a unified view of all events and facilitates cross-component analysis.
- Log Filtering: Use log filtering tools to narrow down the scope of analysis. For example, filter logs by API endpoint, HTTP status code, error message, or timestamp. This reduces the amount of data to be analyzed and helps focus on relevant events.
- Pattern Recognition: Identify patterns in the logs to detect anomalies, performance bottlenecks, and security threats. Look for recurring error messages, unusually high latency, or suspicious activity.
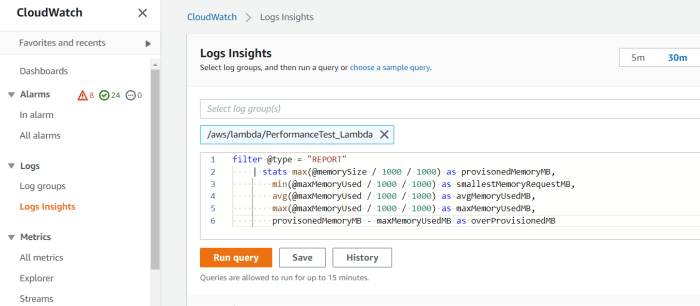
- Performance Profiling: Use Lambda function logs to profile the execution time of different code sections. This helps identify performance bottlenecks, such as slow database queries or inefficient algorithms. Tools like AWS X-Ray can provide detailed tracing information, visualizing the flow of requests through the API.
- Error Analysis: Analyze error logs to understand the causes of failures. Identify the frequency of errors, the affected API endpoints, and the specific error messages. This information can be used to fix bugs, improve error handling, and prevent future issues.
- Example: Suppose a user reports slow response times for a specific API endpoint. By examining the CloudWatch Logs, you can filter logs for that endpoint and identify the Lambda function’s execution time. If the function’s execution time is consistently high, you can then analyze the function’s code to identify and optimize slow operations, such as database queries. Consider a scenario where the Lambda function interacts with a database to retrieve data.
The following formula can be used to calculate the average database query time:
Average Query Time = (Total Query Time) / (Number of Queries)
If the average query time is high, it suggests that the database query is a performance bottleneck.
- Alerting: Set up alerts based on log patterns. For example, create an alert to notify you when the error rate for a specific API endpoint exceeds a predefined threshold. This enables proactive issue detection and faster resolution.
Advanced Configuration and Features
API Gateway offers a suite of advanced features designed to optimize performance, enhance flexibility, and provide robust control over API deployments. These features extend beyond basic request routing and allow for fine-grained management of API behavior, including caching, request transformation, and sophisticated integration options. Effectively utilizing these capabilities is crucial for building scalable, efficient, and secure RESTful APIs.
API Gateway Caching Configuration
API Gateway caching significantly reduces latency and improves the responsiveness of APIs by storing responses from backend services. This feature minimizes the load on backend resources and allows for faster retrieval of frequently accessed data.
To configure API Gateway caching:
- Enable Caching: Caching is enabled at the method level within the API Gateway console. This allows for granular control over which methods benefit from caching.
- Choose Cache Settings: Configuration includes the cache capacity (measured in gigabytes), the time-to-live (TTL) for cached responses (in seconds), and the cache key settings. The cache key determines how responses are stored and retrieved.
- Cache Key Parameters: The cache key is constructed based on parameters such as the HTTP method, request headers, and query string parameters. Selecting the appropriate parameters is critical for ensuring that cached responses are relevant to the incoming requests. For instance, if an API endpoint retrieves user-specific data, the cache key should include a user ID to avoid serving incorrect information.
- Cache Invalidation: While caching improves performance, it’s essential to manage cache invalidation. This involves strategies for removing stale data from the cache. Invalidation can be performed manually through the API Gateway console or programmatically using the AWS SDK. For example, you can use a Lambda function triggered by a database update to invalidate related cache entries.
- Monitoring Cache Performance: API Gateway provides metrics related to cache utilization, hit/miss ratios, and latency. These metrics are available in CloudWatch and should be regularly monitored to assess the effectiveness of caching and identify potential bottlenecks. A low cache hit ratio may indicate that the cache key is not correctly configured or that the TTL is too short.
For example, consider an API endpoint that retrieves product details. By enabling caching and configuring the cache key to include the product ID, API Gateway can cache the product details for a specified TTL. Subsequent requests for the same product ID will be served from the cache, significantly reducing the latency compared to fetching the data from the backend database every time.
The TTL can be set based on how frequently the product details are updated. If product details change frequently, a shorter TTL is appropriate. If they change infrequently, a longer TTL can be used to maximize cache utilization.
API Gateway Integration Features
API Gateway provides various integration features that enable flexible API design and implementation, including mocking and proxying. These features allow developers to simulate API behavior, decouple API design from backend implementation, and handle complex routing scenarios.
- Mocking: Mocking allows you to define API responses without needing a backend service. This is particularly useful during the design and testing phases of API development. You can define static responses for different HTTP methods and paths, enabling developers to test the API’s structure and functionality before the backend is ready.
- Proxying: Proxying enables API Gateway to forward requests to a backend service without significant transformation. This is useful for integrating with existing services, such as legacy systems or third-party APIs. API Gateway acts as a reverse proxy, handling authentication, authorization, and other security features while passing the request to the backend.
Consider a scenario where you are developing an API for a new e-commerce platform. Before the backend services are fully implemented, you can use mocking to simulate responses for product listings, user profiles, and order details. This allows frontend developers to begin building the user interface and test the API endpoints without depending on a live backend. The mocked responses can be based on the expected data format and content.
For proxying, consider an API that needs to integrate with a third-party payment gateway. API Gateway can be configured to proxy requests to the payment gateway, handling the necessary authentication and authorization while forwarding the payment requests. This decouples the API from the specifics of the payment gateway’s implementation, allowing for easier maintenance and future changes.
API Gateway Request Transformation Features
API Gateway’s request transformation features enable you to modify requests before they are sent to the backend and transform responses before they are returned to the client. These features are crucial for adapting requests and responses to match the requirements of the backend service and the client application.
To utilize request transformation:
- Request Mapping Templates: Request mapping templates, often using Velocity Template Language (VTL), allow you to transform the incoming request into a format that the backend service understands. This includes modifying headers, query parameters, and the request body.
- Response Mapping Templates: Response mapping templates, also using VTL, allow you to transform the response from the backend service before returning it to the client. This is useful for formatting the response data, filtering sensitive information, and adapting the response to the client’s needs.
- Data Transformation: Request and response transformation can be used to transform data formats, such as converting between JSON and XML, or mapping data fields to match different naming conventions.
- Header Manipulation: You can add, modify, or remove request and response headers using mapping templates. This is useful for passing metadata, setting security-related headers, and handling CORS (Cross-Origin Resource Sharing).
For example, imagine an API that receives requests in JSON format but needs to send them to a backend service that expects XML. Using a request mapping template, you can transform the JSON request body into an XML format. Conversely, if the backend service returns data in XML format and the client application expects JSON, a response mapping template can be used to convert the XML response into JSON.
The VTL template would parse the incoming JSON or XML and restructure the data based on defined logic, potentially including operations such as data type conversion or string manipulation.
Another example involves transforming query parameters. If a client application sends a query parameter named “product_id”, but the backend service expects “productId”, a request mapping template can be used to rename the parameter before forwarding the request. Similarly, response transformation can be used to redact sensitive data from the response before sending it back to the client, enhancing security.
Best Practices and Optimization
Optimizing RESTful APIs built with API Gateway and Lambda functions is crucial for performance, cost-efficiency, and scalability. This section details best practices to enhance API design, Lambda function execution, and overall system efficiency. Implementing these practices ensures a robust and performant API infrastructure.
API Design Best Practices
Adhering to established API design principles is fundamental for creating maintainable and scalable RESTful APIs. This involves careful consideration of resource modeling, HTTP methods, and response formats.
- Resource Modeling: Design resources that accurately represent the data and functionality of your API. Employ nouns for resource names (e.g., `/users`, `/products`) and use appropriate HTTP methods (GET, POST, PUT, DELETE) to interact with these resources. For example, to retrieve a specific user, the API might use `GET /users/userId`.
- HTTP Method Usage: Utilize HTTP methods correctly.
GETshould retrieve data,POSTshould create new resources,PUTshould update an existing resource entirely,PATCHshould partially update a resource, andDELETEshould remove a resource. Misusing HTTP methods can lead to confusion and errors. - Versioning: Implement API versioning to manage changes without breaking existing clients. Versioning can be achieved through URL paths (e.g., `/v1/users`), custom headers (e.g., `X-API-Version: 1`), or query parameters (e.g., `/users?version=1`). This allows for backward compatibility while introducing new features.
- Input Validation: Thoroughly validate all incoming requests to ensure data integrity and prevent security vulnerabilities. Use schemas (e.g., JSON Schema) to define the expected structure and data types of request bodies and query parameters. API Gateway’s request validation features can automate this process.
- Rate Limiting: Implement rate limiting to protect your API from abuse and ensure fair usage. API Gateway provides built-in rate limiting capabilities, allowing you to define quotas and burst limits. Consider different rate limits for different API endpoints or user tiers.
- Response Formatting: Return consistent and well-formatted responses. Use JSON as the standard response format and include relevant HTTP status codes to indicate the outcome of each request (e.g., 200 OK, 201 Created, 400 Bad Request, 500 Internal Server Error). Provide meaningful error messages to aid in debugging.
- Documentation: Provide comprehensive API documentation using tools like OpenAPI (Swagger). Clear documentation helps developers understand and integrate with your API effectively. Automated documentation generation can ensure that your documentation stays up-to-date with your API’s evolution.
Lambda Function Optimization
Optimizing Lambda function performance is critical for reducing latency and costs. Several strategies can be employed to achieve optimal function execution.
- Code Optimization: Write efficient and optimized code. Profile your code to identify performance bottlenecks and address them. Use appropriate data structures and algorithms. Minimize the use of computationally expensive operations.
- Language Selection: Choose the right programming language for your use case. Consider the performance characteristics of each language (e.g., Python, Node.js, Java, Go). For CPU-intensive tasks, compiled languages like Java or Go may offer better performance. For I/O-bound tasks, languages with good asynchronous support like Node.js or Python’s asyncio might be suitable.
- Dependency Management: Minimize the size of your deployment package by only including necessary dependencies. Use package managers effectively (e.g., npm, pip, Maven) and avoid bundling unnecessary libraries. Consider using Lambda layers to share common dependencies across multiple functions.
- Concurrency Management: Configure the appropriate concurrency settings for your Lambda functions. Consider the expected traffic volume and the processing time of each function invocation. Monitor function metrics to identify and address potential concurrency issues. AWS Lambda allows you to set reserved concurrency to limit the number of concurrent executions.
- Memory Allocation: Allocate sufficient memory to your Lambda functions. The amount of memory allocated directly impacts the CPU power available to the function. Monitor function performance and adjust memory allocation as needed to balance performance and cost. The trade-off is that more memory can result in higher cost, but also in faster execution times.
- Cold Start Optimization: Minimize cold start times, especially for functions that are invoked frequently. Use provisioned concurrency to keep functions warm and ready to serve requests. Optimize your code to reduce initialization time, such as by deferring initialization of heavy objects.
- Caching: Implement caching to reduce the load on your Lambda functions and improve response times. Use API Gateway’s caching capabilities or integrate with external caching services (e.g., Redis, Memcached). Cache frequently accessed data to avoid repeated database calls.
- Asynchronous Processing: For tasks that don’t require an immediate response, use asynchronous processing techniques. Offload tasks to queues (e.g., SQS, Kinesis) to decouple the API from the processing workload. This can improve responsiveness and reduce the load on your Lambda functions.
Cloud Provider Comparison
The following table compares API Gateway and Lambda function offerings from different cloud providers, highlighting key features and pricing considerations. Pricing is complex and depends on various factors; the values presented are representative and subject to change. Always consult the provider’s official documentation for the most up-to-date pricing information.
| Provider | API Gateway Features | Lambda Features | Pricing |
|---|---|---|---|
| AWS |
|
|
|
| Google Cloud |
|
|
|
| Microsoft Azure |
|
|
|
Last Point
In conclusion, the strategic integration of API Gateway with Lambda functions offers a potent solution for constructing resilient, scalable, and cost-effective RESTful APIs. By understanding the underlying principles, configurations, and best practices Artikeld in this analysis, developers can harness the full potential of serverless architectures to create efficient and high-performing applications. This approach not only streamlines the development process but also provides significant advantages in terms of scalability, maintainability, and operational efficiency, making it a cornerstone of modern API design.
Frequently Asked Questions
What are the primary cost considerations when using API Gateway and Lambda functions?
The cost is primarily determined by the number of API requests, the duration of Lambda function execution, and data transfer. API Gateway charges based on the number of requests and data transfer, while Lambda charges are based on compute time and memory allocation. Careful optimization of function execution time and efficient API design are crucial for cost management.
How does API Gateway handle authentication and authorization?
API Gateway supports several authentication mechanisms, including API keys, IAM roles, and JWT (JSON Web Tokens). Authorization can be implemented using IAM policies, custom authorizers (Lambda functions that validate tokens), or by integrating with third-party identity providers. The choice depends on the specific security requirements and complexity of the API.
What are the limitations of using API Gateway and Lambda functions?
Limitations include the cold start time of Lambda functions, which can affect latency, especially for infrequently accessed APIs. Also, the maximum execution time of Lambda functions is limited, and the maximum request/response size in API Gateway has constraints. Proper design and optimization are essential to mitigate these limitations.
How can I monitor the performance of my API?
API Gateway provides built-in monitoring metrics like latency, error rates, and request counts. These metrics can be accessed through the cloud provider’s monitoring services (e.g., CloudWatch in AWS). Additionally, setting up detailed logging for both API Gateway and Lambda functions allows for in-depth analysis of API behavior and debugging.