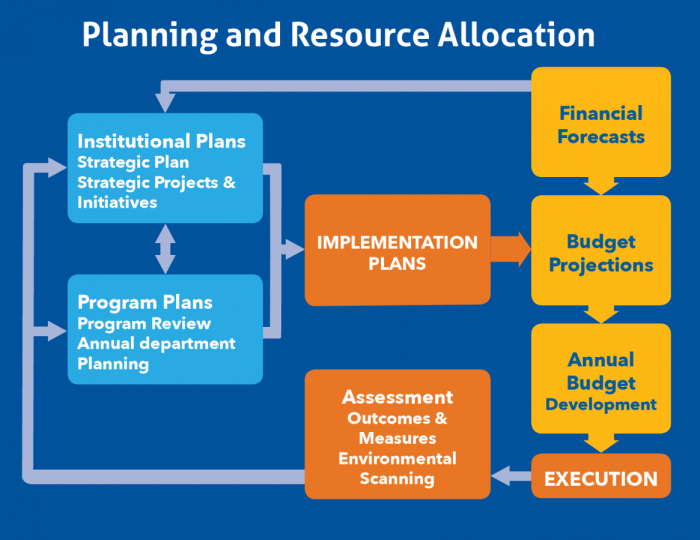
Embarking on a journey through the realm of serverless computing necessitates a robust and scalable database solution. How to use Amazon DynamoDB for serverless applications, a fully managed NoSQL database service, emerges as a pivotal component in this landscape. Its inherent characteristics, including high availability, automatic scaling, and pay-per-use pricing, render it exceptionally well-suited for the dynamic demands of serverless architectures.
This exploration delves into the intricacies of integrating DynamoDB within serverless applications, providing a comprehensive understanding of its benefits, practical implementation, and optimization strategies.
This discourse will navigate the critical aspects of DynamoDB utilization, from establishing tables and integrating with AWS Lambda functions to ensuring data security, handling transactions, and optimizing performance. We will examine the integration with API Gateway for building scalable APIs, leveraging DynamoDB Streams for real-time functionalities, and employing advanced features like Global Tables and DynamoDB Accelerator (DAX). Through practical examples and best practices, we aim to equip developers with the knowledge and tools to effectively leverage DynamoDB in their serverless projects, fostering efficient, scalable, and cost-effective applications.
Introduction to Amazon DynamoDB for Serverless Applications
DynamoDB, a fully managed NoSQL database service provided by Amazon Web Services, is a cornerstone for building scalable and highly available serverless applications. Its design principles align perfectly with the serverless paradigm, offering a seamless experience for developers focused on functionality rather than infrastructure management. DynamoDB’s ability to handle massive scale with predictable performance makes it an ideal choice for a variety of serverless use cases.
Core Benefits of Using DynamoDB in a Serverless Architecture
DynamoDB provides several key advantages when integrated into a serverless architecture. These benefits streamline development, reduce operational overhead, and enhance application performance.
- Scalability and Elasticity: DynamoDB automatically scales to accommodate fluctuating workloads. It handles increases in traffic and data volume without manual intervention, ensuring consistent performance. This is crucial for serverless applications, which often experience unpredictable spikes in demand. For example, an e-commerce application might experience a surge in traffic during a flash sale. DynamoDB can automatically scale its resources to handle the increased read and write requests without any downtime or performance degradation.
- Pay-per-use Pricing: DynamoDB’s pay-per-use pricing model aligns with the serverless philosophy of only paying for the resources consumed. This eliminates the need to provision and pay for idle capacity, optimizing cost efficiency. This is especially beneficial for applications with variable workloads.
- Fully Managed Service: DynamoDB is a fully managed service, meaning that AWS handles all the underlying infrastructure management tasks, such as hardware provisioning, software patching, and backups. This allows developers to focus on writing code and building features, rather than managing database infrastructure.
- High Availability and Durability: DynamoDB is designed for high availability and durability, with data automatically replicated across multiple Availability Zones within a region. This ensures that data is always available, even in the event of a failure.
- Integration with AWS Services: DynamoDB seamlessly integrates with other AWS services, such as AWS Lambda and API Gateway, simplifying the development and deployment of serverless applications. This integration streamlines the process of creating and managing serverless applications.
Common Use Cases Where DynamoDB Excels in Serverless Environments
DynamoDB’s capabilities make it well-suited for various serverless application scenarios. These examples demonstrate its versatility and effectiveness.
- Web Applications: DynamoDB is frequently used to store user profiles, session data, and application metadata for web applications. Its scalability and low latency make it ideal for handling large numbers of concurrent users. For instance, a social media platform can use DynamoDB to store user data, posts, and interactions. The ability to quickly retrieve user profiles and content feeds ensures a responsive user experience.
- Mobile Applications: Mobile apps often rely on DynamoDB for storing user data, game scores, and other application-specific information. Its ability to handle large volumes of data and provide low-latency access makes it suitable for mobile applications with a global user base. Consider a mobile gaming app. DynamoDB can store player profiles, game scores, and leaderboards. The service’s speed and scalability enable fast access to player data, even with millions of active users.
- IoT Applications: DynamoDB is a popular choice for storing time-series data from IoT devices. Its ability to handle high write throughput makes it well-suited for ingesting large volumes of sensor data. An example would be a smart home system collecting data from various sensors (temperature, humidity, etc.). DynamoDB can store this data, enabling analysis and visualization of environmental conditions.
- E-commerce Applications: DynamoDB is used to store product catalogs, shopping carts, and order information in e-commerce applications. Its scalability and high availability ensure that these applications can handle peak traffic during sales events. An online retailer can use DynamoDB to store product information, including descriptions, pricing, and inventory levels. The database’s ability to handle a large number of reads and writes ensures that customers can browse products and place orders without any performance issues.
- Content Management Systems (CMS): DynamoDB can store content metadata, such as articles, blog posts, and images, for CMS platforms. Its flexibility allows for efficient content storage and retrieval. A blog platform can utilize DynamoDB to store articles, author information, and comments. DynamoDB’s ability to quickly retrieve and display content ensures a smooth user experience.
High-Level Overview of DynamoDB Integration with AWS Lambda and API Gateway
The seamless integration between DynamoDB, AWS Lambda, and API Gateway forms the foundation for many serverless applications. This integration enables developers to build scalable, event-driven, and cost-effective solutions.
- AWS Lambda: AWS Lambda functions can directly interact with DynamoDB tables. Lambda functions can be triggered by various events, such as API calls through API Gateway, changes in DynamoDB tables (using DynamoDB Streams), or scheduled events. These functions can then read from, write to, or update data in DynamoDB. For example, a Lambda function can be triggered by a new user registration (via API Gateway) to write user data to a DynamoDB table.
- API Gateway: API Gateway acts as the front door for serverless applications. It exposes REST APIs that can trigger Lambda functions. These Lambda functions can then interact with DynamoDB. This allows developers to build APIs that perform CRUD (Create, Read, Update, Delete) operations on data stored in DynamoDB. For instance, an API Gateway endpoint can be configured to trigger a Lambda function that retrieves a product from a DynamoDB table based on its ID.
- Workflow: A typical workflow involves a user making a request to an API Gateway endpoint. API Gateway then invokes a Lambda function. The Lambda function interacts with DynamoDB to perform the requested operation (e.g., reading data, writing data, updating data). The Lambda function then returns a response to API Gateway, which, in turn, returns the response to the user. This entire process is orchestrated without the need to manage any servers.
Setting Up DynamoDB Tables for Serverless Projects
DynamoDB’s flexibility and scalability make it an ideal choice for serverless applications. Properly configuring DynamoDB tables is crucial for performance, cost optimization, and overall application success. This section details the process of creating DynamoDB tables, designing effective schemas, and configuring capacity settings.
Creating a DynamoDB Table with Primary Keys and Attributes
Creating a DynamoDB table involves defining its structure, including primary keys and attributes. The primary key uniquely identifies each item within the table, while attributes store the data associated with that item.The following steps Artikel the process:
- Define the Table Name: Choose a descriptive and meaningful name that reflects the data stored in the table. This name is used to identify the table within your AWS account.
- Choose a Primary Key: Select a primary key based on how your application will access data. DynamoDB supports two types of primary keys:
- Partition Key (Hash Key): This key determines the partition where the item is stored. DynamoDB uses the hash key value to calculate a hash and distribute data across partitions.
- Partition Key and Sort Key (Hash and Range Key): This key combination provides a more flexible way to access data. The partition key determines the partition, and the sort key allows for efficient querying and sorting of items within that partition.
- Define Attributes: Specify the attributes that will store the data for each item. Each attribute has a name and a data type. Common data types include string, number, boolean, list, map, and binary.
- Configure Capacity Settings: Choose between provisioned and on-demand capacity modes. Provisioned capacity requires specifying read and write capacity units, while on-demand capacity automatically scales to handle the workload.
- Create the Table: Use the AWS Management Console, AWS CLI, or an infrastructure-as-code tool like Terraform to create the table.
For example, consider creating a table named “Users” with the following structure:
- Table Name: Users
- Primary Key:
- Partition Key: “UserID” (String)
- Attributes:
- “Username” (String)
- “Email” (String)
- “RegistrationDate” (Number – representing a Unix timestamp)
- “IsActive” (Boolean)
This table design allows for efficient retrieval of user data based on the unique “UserID.”
Designing a Table Schema for a Specific Serverless Application Scenario (e.g., User Profiles, To-Do Lists)
Designing an effective table schema is critical for optimizing performance and cost. The schema should reflect how data will be accessed and queried. The following examples demonstrate schema design for two common serverless application scenarios: user profiles and to-do lists. Scenario 1: User ProfilesConsider a serverless application managing user profiles. The requirements include storing user information (username, email, profile picture URL, registration date) and allowing for efficient retrieval based on user ID and querying by username.The following schema can be implemented:
- Table Name: UserProfiles
- Primary Key:
- Partition Key: “UserID” (String)
- Attributes:
- “Username” (String)
- “Email” (String)
- “ProfilePictureURL” (String)
- “RegistrationDate” (Number – Unix timestamp)
- Secondary Indexes:
- Global Secondary Index (GSI): “UsernameIndex” with “Username” as the partition key. This allows for efficient querying of users by username.
This design prioritizes efficient retrieval by UserID (primary key) and provides a GSI for searching by username. The choice of “UserID” as the partition key ensures data distribution and scalability. Scenario 2: To-Do ListsFor a to-do list application, the requirements involve storing tasks associated with users, allowing users to create, read, update, and delete tasks. Efficient querying and sorting of tasks based on due date and status are necessary.The following schema can be implemented:
- Table Name: ToDoLists
- Primary Key:
- Partition Key: “UserID” (String)
- Sort Key: “TaskID” (String)
- Attributes:
- “TaskDescription” (String)
- “DueDate” (Number – Unix timestamp)
- “Status” (String – e.g., “Open”, “In Progress”, “Completed”)
This design utilizes a composite primary key (UserID and TaskID) for unique task identification. The UserID allows for efficient retrieval of all tasks for a specific user. The TaskID ensures unique identification within a user’s list. The sort key allows for efficient querying of tasks.
Organizing Table Capacity Settings (Provisioned vs. On-Demand) and Their Implications
DynamoDB offers two capacity modes: provisioned and on-demand. The choice between these modes significantly impacts cost and performance.
- Provisioned Capacity: In this mode, you specify the read and write capacity units (RCUs and WCUs) for your table. DynamoDB reserves the specified capacity. This mode is suitable for applications with predictable traffic patterns.
- On-Demand Capacity: This mode automatically scales capacity based on the workload. You don’t need to manage capacity; DynamoDB handles scaling. This mode is ideal for applications with unpredictable or spiky traffic patterns.
The implications of each capacity mode are:
- Cost: Provisioned capacity has a fixed cost based on the provisioned RCUs and WCUs. On-demand capacity charges based on actual usage. On-demand can be more cost-effective for applications with low or fluctuating traffic, while provisioned can be cheaper for consistent, high-volume workloads.
- Performance: Provisioned capacity ensures consistent performance as long as you provision sufficient capacity. On-demand capacity may experience initial latency spikes as it scales up.
- Management Overhead: Provisioned capacity requires monitoring and capacity adjustments to optimize cost and performance. On-demand capacity simplifies capacity management.
Consider a scenario where a serverless application processes user profile updates. If the application experiences predictable, consistent traffic, provisioned capacity might be suitable, allowing for cost optimization by right-sizing the capacity. However, if the application experiences sudden traffic spikes, such as during a marketing campaign, on-demand capacity would be the preferred choice to ensure consistent performance without manual capacity adjustments.
For example, a news website that sees significant traffic increases during major news events could benefit from on-demand capacity to handle the surge without manual intervention. In contrast, a system managing sensor data with relatively constant data ingestion rates might find provisioned capacity more cost-effective.
Integrating DynamoDB with AWS Lambda Functions
Integrating Amazon DynamoDB with AWS Lambda functions is a cornerstone of building scalable and responsive serverless applications. This integration allows developers to create event-driven architectures where Lambda functions can be triggered by various events, such as changes in DynamoDB tables, and perform operations like data processing, analysis, and updates. The efficiency of this integration hinges on the proper handling of database connections, efficient data access patterns, and adherence to best practices for resource management within the Lambda environment.
Writing Lambda Functions Interacting with DynamoDB
Lambda functions interact with DynamoDB using the AWS SDK for the programming language of choice (e.g., Boto3 for Python, AWS SDK for JavaScript, etc.). The SDK provides a set of APIs that allow developers to perform CRUD (Create, Read, Update, Delete) operations on DynamoDB tables. Understanding these APIs and how to use them effectively is crucial for building robust and efficient serverless applications.The following example demonstrates a Python Lambda function interacting with DynamoDB.
The function retrieves an item from a DynamoDB table based on a provided primary key.“`pythonimport boto3import jsondef lambda_handler(event, context): “”” Retrieves an item from a DynamoDB table. Args: event (dict): Event data containing the primary key. context (object): Lambda context object.
Returns: dict: A dictionary containing the retrieved item or an error message. “”” try: # Initialize DynamoDB client dynamodb = boto3.resource(‘dynamodb’) table_name = ‘YourTableName’ # Replace with your table name table = dynamodb.Table(table_name) # Extract the primary key from the event item_id = event[‘itemId’] # Retrieve the item from DynamoDB response = table.get_item( Key= ‘itemId’: item_id ) # Check if the item was found if ‘Item’ in response: item = response[‘Item’] return ‘statusCode’: 200, ‘body’: json.dumps(item) else: return ‘statusCode’: 404, ‘body’: json.dumps(‘message’: ‘Item not found’) except Exception as e: print(f”Error: e”) return ‘statusCode’: 500, ‘body’: json.dumps(‘message’: ‘Internal server error’) “`This function first initializes a DynamoDB resource using `boto3.resource(‘dynamodb’)`.
It then specifies the table name. The primary key is extracted from the event payload. The `table.get_item()` method retrieves the item based on the key. The function returns a success response with the item if found, or a 404 error if not found. Error handling is included to catch and report exceptions.
The `event` object typically contains information passed to the Lambda function, such as data from an API Gateway request or an event from another AWS service. The `context` object provides information about the invocation, function, and execution environment.
Best Practices for Handling Database Connections and Resource Management within Lambda
Efficiently managing database connections and resources within Lambda functions is crucial for performance and cost optimization. Lambda functions are stateless and short-lived, and connections should be handled accordingly.Here are some best practices:
- Connection Initialization: Initialize the DynamoDB client outside the handler function. This way, the client can be reused across multiple invocations of the function within the same execution environment (container), reducing the overhead of creating a new connection for each invocation. This is achieved by declaring the `dynamodb = boto3.resource(‘dynamodb’)` line outside the `lambda_handler` function.
- Resource Reuse: Leverage the Lambda execution environment to reuse resources. The Lambda service often reuses execution environments for subsequent invocations of the same function, especially if the function is invoked frequently. Avoid creating and destroying resources unnecessarily.
- Error Handling: Implement comprehensive error handling to gracefully manage exceptions that may occur during database operations. Log errors to CloudWatch for debugging and monitoring. Include `try…except` blocks to catch potential exceptions.
- Connection Pooling (Not Applicable Directly): While traditional connection pooling is not directly applicable to Lambda’s ephemeral nature, the principle of resource reuse applies. The Lambda service itself manages the underlying infrastructure, including connection reuse to optimize performance.
- Provisioned Throughput: Configure provisioned throughput appropriately for your DynamoDB tables. Under-provisioning can lead to throttling and performance degradation. Over-provisioning can lead to unnecessary costs. Monitor table metrics in CloudWatch to determine the optimal throughput settings.
- Use of Environment Variables: Store sensitive information, such as table names, in environment variables. This makes the code more portable and secure, and avoids hardcoding sensitive data within the function code.
- Idempotency: Design functions to be idempotent, meaning that running the same operation multiple times has the same effect as running it once. This is especially important for write operations to handle retries and potential failures.
Code Example: CRUD Operations in DynamoDB
The following code example demonstrates a comprehensive set of CRUD operations using a Python Lambda function. It covers reading, writing, updating, and deleting data from a DynamoDB table. This example assumes the existence of a DynamoDB table named “MyTable” with a primary key “id” of type String.“`pythonimport boto3import jsondef lambda_handler(event, context): “”” Performs CRUD operations on a DynamoDB table.
Args: event (dict): Event data containing the operation and data. context (object): Lambda context object. Returns: dict: A dictionary containing the result of the operation. “”” try: # Initialize DynamoDB client dynamodb = boto3.resource(‘dynamodb’) table_name = ‘MyTable’ # Replace with your table name table = dynamodb.Table(table_name) operation = event[‘operation’] if operation == ‘create’: item = event[‘item’] response = table.put_item(Item=item) return ‘statusCode’: 200, ‘body’: json.dumps(‘message’: ‘Item created successfully’, ‘response’: response) elif operation == ‘read’: item_id = event[‘id’] response = table.get_item(Key=’id’: item_id) if ‘Item’ in response: return ‘statusCode’: 200, ‘body’: json.dumps(response[‘Item’]) else: return ‘statusCode’: 404, ‘body’: json.dumps(‘message’: ‘Item not found’) elif operation == ‘update’: item_id = event[‘id’] update_expression = event[‘updateExpression’] expression_attribute_values = event[‘expressionAttributeValues’] response = table.update_item( Key=’id’: item_id, UpdateExpression=update_expression, ExpressionAttributeValues=expression_attribute_values, ReturnValues=”UPDATED_NEW” ) return ‘statusCode’: 200, ‘body’: json.dumps(‘message’: ‘Item updated successfully’, ‘attributes’: response[‘Attributes’]) elif operation == ‘delete’: item_id = event[‘id’] response = table.delete_item(Key=’id’: item_id) return ‘statusCode’: 200, ‘body’: json.dumps(‘message’: ‘Item deleted successfully’, ‘response’: response) else: return ‘statusCode’: 400, ‘body’: json.dumps(‘message’: ‘Invalid operation’) except Exception as e: print(f”Error: e”) return ‘statusCode’: 500, ‘body’: json.dumps(‘message’: ‘Internal server error’) “`This function is designed to handle multiple CRUD operations based on the `operation` field in the event payload.
- Create: The `create` operation uses the `put_item()` method to add a new item to the table. The `item` data is passed in the event.
- Read: The `read` operation uses the `get_item()` method to retrieve an item based on its ID.
- Update: The `update` operation uses the `update_item()` method to modify an existing item. It uses an `updateExpression` and `expressionAttributeValues` for flexible updates.
- Delete: The `delete` operation uses the `delete_item()` method to remove an item from the table.
- Error Handling: The function includes error handling to catch exceptions and return appropriate HTTP status codes.
This comprehensive example provides a practical guide to integrating Lambda functions with DynamoDB for common data management tasks. The `event` object is structured to contain all necessary data, including the operation type and the data to be operated on.
Securing DynamoDB Access in Serverless Applications

Securing access to Amazon DynamoDB is paramount in serverless applications to protect sensitive data and maintain the integrity of the system. This involves controlling who can access the database, what actions they can perform, and how data is protected both at rest and in transit. Implementing robust security measures is crucial to prevent unauthorized access, data breaches, and compliance violations.
IAM Roles and Policies for DynamoDB Access
Identity and Access Management (IAM) roles and policies are fundamental to securing DynamoDB access. IAM allows defining permissions that dictate which actions users, groups, or services (like Lambda functions) can perform on DynamoDB resources. These permissions are governed by policies, which are JSON documents that specify the allowed or denied actions.IAM roles are particularly important in serverless architectures. Lambda functions, for instance, assume IAM roles to gain the necessary permissions to interact with other AWS services, including DynamoDB.
When a Lambda function is invoked, it uses the credentials associated with its assigned IAM role.
- IAM Policies: IAM policies define the specific permissions. There are two primary types: identity-based policies and resource-based policies.
- Identity-based policies: These policies are attached to IAM users, groups, or roles, specifying what actions they can perform. For example, a policy could grant a Lambda function the `dynamodb:GetItem` and `dynamodb:PutItem` permissions on a specific DynamoDB table.
- Resource-based policies: These policies are attached to the DynamoDB table itself and control who can access the table. While less common in serverless applications, they can be used to grant cross-account access or manage access from specific AWS services.
- Least Privilege Principle: The principle of least privilege dictates that entities should be granted only the minimum necessary permissions to perform their tasks. This reduces the attack surface and minimizes the impact of potential security breaches. For example, a Lambda function that only needs to read data from a DynamoDB table should be granted only the `dynamodb:GetItem` permission, not the broader `dynamodb:*` permission, which would allow it to perform all actions.
- Policy Structure: IAM policies are written in JSON and include elements such as `Effect` (Allow or Deny), `Action` (the specific DynamoDB operations, such as `GetItem`, `PutItem`, `Scan`, etc.), and `Resource` (the DynamoDB table or specific items).
- Example Policy for a Lambda Function: A policy that allows a Lambda function to read and write to a DynamoDB table named “MyTable” might look like this:
"Version": "2012-10-17", "Statement": [ "Effect": "Allow", "Action": [ "dynamodb:GetItem", "dynamodb:PutItem", "dynamodb:UpdateItem", "dynamodb:DeleteItem" ], "Resource": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/MyTable" ]This policy grants the Lambda function the ability to perform GetItem, PutItem, UpdateItem, and DeleteItem operations on the specified DynamoDB table.
Replace `REGION` and `ACCOUNT_ID` with the appropriate values.
Implementing Least-Privilege Access Control for Lambda Functions
Implementing least-privilege access control for Lambda functions interacting with DynamoDB involves carefully crafting IAM policies that grant only the necessary permissions for each function’s specific tasks. This minimizes the potential damage if a function is compromised.
- Analyze Function Requirements: Before creating an IAM policy, analyze the specific operations a Lambda function needs to perform on DynamoDB. Does it need to read data, write data, update items, or delete items? Does it need to access the entire table or only specific items?
- Create Specific Policies: Create IAM policies that reflect the function’s requirements. Avoid using wildcard permissions (e.g., `dynamodb:*`) unless absolutely necessary. Instead, specify the exact DynamoDB actions required (e.g., `dynamodb:GetItem`, `dynamodb:PutItem`).
- Use Resource-Level Permissions: If possible, use resource-level permissions to restrict access to specific DynamoDB tables or even specific items within a table. This provides a more granular level of control. For example, you can use the `Condition` element in an IAM policy to allow access only to items with a specific attribute value.
- Regular Auditing and Review: Regularly audit and review IAM policies to ensure they remain aligned with the function’s needs and to identify any unnecessary permissions. This helps prevent permission creep, where functions accumulate more permissions than they require over time.
- Example: Limiting Access to Specific Items: Suppose a Lambda function needs to read data from a DynamoDB table, but only for items with a specific partition key value. The following IAM policy can be used to achieve this:
"Version": "2012-10-17", "Statement": [ "Effect": "Allow", "Action": [ "dynamodb:GetItem" ], "Resource": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/MyTable", "Condition": "ForAllValues:StringEquals": "dynamodb:LeadingKeys": [ "specific_partition_key_value" ] ]This policy allows the function to only retrieve items where the partition key matches “specific_partition_key_value”.
Encryption at Rest and In Transit for DynamoDB Data
Encryption is a critical security measure to protect data confidentiality. DynamoDB offers encryption both at rest and in transit to ensure data is protected from unauthorized access.
- Encryption at Rest: DynamoDB supports encryption at rest using AWS Key Management Service (KMS) keys. This means that data stored on DynamoDB servers is encrypted using KMS keys.
- Managed Keys: By default, DynamoDB uses an AWS-managed key. This key is managed by AWS and requires no configuration. While it provides a baseline level of security, it offers less control over key management.
- Customer-Managed Keys: You can choose to use customer-managed keys (CMKs) stored in KMS. This provides greater control over the encryption keys, including the ability to rotate keys, define key policies, and audit key usage.
- Enabling Encryption: Encryption at rest can be enabled when creating a DynamoDB table or updated later. It’s generally recommended to enable encryption at rest for all tables.
- Data Protection: When encryption at rest is enabled, all data stored in the DynamoDB table, including indexes and backups, is encrypted. The encryption process is transparent to the application; DynamoDB handles the encryption and decryption automatically.
- Encryption in Transit: DynamoDB uses HTTPS for all communication between clients and the service. This ensures that data transmitted between your application and DynamoDB is encrypted in transit, protecting it from eavesdropping.
- HTTPS: All API calls to DynamoDB are made over HTTPS, which uses Transport Layer Security (TLS) to encrypt the communication. This ensures that data is protected while in transit.
- TLS Versions: AWS regularly updates its TLS configurations to support the latest security standards and protocols.
- Certificate Verification: Clients (e.g., Lambda functions, applications) should always verify the server’s certificate to prevent man-in-the-middle attacks. AWS provides the necessary certificates for this purpose.
- Key Rotation and Management: If using customer-managed keys, it’s essential to regularly rotate the encryption keys. Key rotation involves generating new keys and re-encrypting the data using the new keys. This process limits the impact of a potential key compromise. KMS provides automated key rotation capabilities.
- Key Policies: Key policies define who can access and manage the KMS keys.
These policies should be carefully configured to restrict access to authorized users and services.
- Auditing: KMS provides detailed audit logs that track all key usage, including who accessed the keys, when they were accessed, and what actions were performed. This information is crucial for security monitoring and incident response.
- Key Policies: Key policies define who can access and manage the KMS keys.
- Example: Enabling Encryption at Rest using Customer-Managed Key:
- Step 1: Create a KMS Key: Create a customer-managed key in KMS. Define the key policy to allow DynamoDB to use the key and to grant access to authorized users.
- Step 2: Create a DynamoDB Table: When creating the DynamoDB table, select the option to enable encryption using a customer-managed key. Specify the ARN (Amazon Resource Name) of the KMS key you created.
Handling Data Consistency and Transactions in DynamoDB
Data consistency and the ability to execute atomic operations are paramount in ensuring the reliability and integrity of data within any database system, including DynamoDB. Serverless applications, often dealing with concurrent requests and distributed architectures, benefit significantly from robust consistency models and transactional capabilities. Understanding these aspects is critical for building scalable and dependable applications.
Consistency Models in DynamoDB
DynamoDB offers two primary consistency models to accommodate different application requirements and performance trade-offs. Choosing the appropriate model is crucial for optimizing read performance and ensuring data correctness.
- Eventually Consistent Reads: This is the default read consistency model. In this model, the read might reflect the most recent write, or it might reflect a slightly older version of the data. The eventual consistency typically propagates within a second, but there’s no guarantee of immediate consistency. This model provides the best read performance and is suitable for applications where eventual consistency is acceptable, such as reading data for analytics or displaying user profiles.
- Strongly Consistent Reads: This model guarantees that a read operation returns the most up-to-date version of the data. It ensures that the read reflects all prior successful write operations. However, strongly consistent reads can have higher latency than eventually consistent reads because they need to query multiple replicas to ensure the latest data is returned. This model is ideal for applications where data accuracy is critical, such as financial transactions or managing inventory levels.
To specify the consistency model, you can use the `ConsistentRead` parameter when performing a read operation. For example, in the AWS SDK for JavaScript (v3), you would set `ConsistentRead: true` for strongly consistent reads and omit the parameter or set it to `false` for eventually consistent reads.
Implementing Atomic Operations and Transactions
DynamoDB provides several mechanisms to ensure data integrity, including atomic operations and transactions. Atomic operations modify a single item, while transactions allow for multiple item operations to be performed as a single unit.
- Atomic Operations: These operations allow you to update a single item in a safe and reliable manner. DynamoDB offers atomic counters, which allow you to increment or decrement a numeric attribute atomically. This is useful for tracking metrics such as the number of page views or the number of items in a shopping cart. You can also use conditional updates to update an item only if a specific condition is met.
- Transactions: DynamoDB transactions provide ACID (Atomicity, Consistency, Isolation, Durability) properties for multiple item operations. Transactions allow you to read, write, and delete multiple items across different tables in a single operation. If any operation within a transaction fails, the entire transaction is rolled back, ensuring data consistency. Transactions are implemented using the `TransactWriteItems` and `TransactGetItems` APIs.
Consider the following JavaScript example using the AWS SDK for JavaScript (v3) to demonstrate an atomic counter:
“`javascript
import DynamoDBClient, UpdateItemCommand from “@aws-sdk/client-dynamodb”;
import marshall, unmarshall from “@aws-sdk/util-dynamodb”;
const client = new DynamoDBClient();
async function incrementCounter(tableName, key, attributeName, incrementBy)
const params =
TableName: tableName,
Key: marshall(key),
UpdateExpression: “ADD #attributeName :incrementBy”,
ExpressionAttributeNames:
“#attributeName”: attributeName,
,
ExpressionAttributeValues: marshall(
“:incrementBy”: incrementBy,
),
ReturnValues: “UPDATED_NEW”,
;
const command = new UpdateItemCommand(params);
const response = await client.send(command);
return unmarshall(response.Attributes);
// Example usage:
async function exampleUsage()
const tableName = “MyTable”;
const key = id: “123” ;
const attributeName = “counter”;
const incrementBy = 1;
const updatedItem = await incrementCounter(tableName, key, attributeName, incrementBy);
console.log(“Updated item:”, updatedItem);
exampleUsage();
“`
This example uses the `UpdateItem` operation with the `ADD` update expression to atomically increment the `counter` attribute.
For transactions, the following JavaScript example demonstrates how to use the `TransactWriteItems` API to update two items atomically:
“`javascript
import DynamoDBClient, TransactWriteItemsCommand from “@aws-sdk/client-dynamodb”;
import marshall, unmarshall from “@aws-sdk/util-dynamodb”;
const client = new DynamoDBClient();
async function performTransaction(tableName1, key1, attributeName1, newValue1, tableName2, key2, attributeName2, newValue2)
const params =
TransactItems: [
Update:
TableName: tableName1,
Key: marshall(key1),
UpdateExpression: “SET #attributeName = :newValue”,
ExpressionAttributeNames:
“#attributeName”: attributeName1,
,
ExpressionAttributeValues: marshall(
“:newValue”: newValue1,
),
,
,
Update:
TableName: tableName2,
Key: marshall(key2),
UpdateExpression: “SET #attributeName = :newValue”,
ExpressionAttributeNames:
“#attributeName”: attributeName2,
,
ExpressionAttributeValues: marshall(
“:newValue”: newValue2,
),
,
,
],
;
const command = new TransactWriteItemsCommand(params);
try
const response = await client.send(command);
console.log(“Transaction successful:”, response);
catch (error)
console.error(“Transaction failed:”, error);
// Example usage:
async function exampleTransaction()
const tableName1 = “Table1”;
const key1 = id: “item1” ;
const attributeName1 = “status”;
const newValue1 = “processed”;
const tableName2 = “Table2”;
const key2 = id: “order123” ;
const attributeName2 = “orderStatus”;
const newValue2 = “shipped”;
await performTransaction(tableName1, key1, attributeName1, newValue1, tableName2, key2, attributeName2, newValue2);
exampleTransaction();
“`
This code snippet updates two items across different tables within a single transaction. If either update fails, both updates are rolled back, maintaining data consistency.
Scenarios for Transactional Operations in Serverless Contexts
Transactions are essential in serverless applications for maintaining data integrity in scenarios involving multiple item updates. These scenarios often involve concurrent requests and distributed operations, where ensuring atomicity is critical.
- Financial Transactions: When transferring funds between accounts, a transaction ensures that the debit from one account and the credit to another either both succeed or both fail, preventing data corruption. Consider an example of a payment processing system:
A user attempts to transfer $100 from their checking account to their savings account. The system uses a DynamoDB transaction to debit $100 from the checking account and credit $100 to the savings account simultaneously. If either operation fails (e.g., due to insufficient funds or a network issue), the entire transaction is rolled back, ensuring the accounts remain consistent.
- Order Processing: In e-commerce applications, transactions can be used to update inventory levels, create order records, and adjust customer balances atomically.
A customer places an order for a product. The serverless application uses a DynamoDB transaction to: decrease the product’s inventory count, create a new order record, and update the customer’s order history. If the inventory update fails (e.g., due to insufficient stock), the order creation and customer history updates are also rolled back.
- Multi-Step Workflows: Transactions can be used to manage complex workflows where multiple steps are required to complete a task.
An application that manages a content publishing workflow. When a new article is published, the application uses a transaction to: update the article’s status to “published”, create a new entry in a search index table, and update the author’s activity log. If any step fails (e.g., search index update fails), all other operations within the transaction are rolled back.
By utilizing transactions in these serverless contexts, developers can ensure data consistency and reliability, even in the face of concurrent requests and potential failures.
Optimizing DynamoDB Performance for Serverless Workloads
Optimizing DynamoDB performance is crucial for serverless applications to ensure scalability, cost-effectiveness, and responsiveness. Serverless architectures often experience fluctuating workloads, and DynamoDB’s ability to scale on demand is a key advantage. However, without proper optimization, performance bottlenecks can arise, impacting application performance and potentially increasing costs. This section details strategies for maximizing DynamoDB’s efficiency in a serverless context.
Strategies for Optimizing Read and Write Performance in DynamoDB
Efficient data modeling is the cornerstone of DynamoDB performance. Careful design of your data structure directly impacts read and write operations. Understanding access patterns and anticipating query requirements are essential.
- Efficient Data Modeling: The choice of partition key and sort key is paramount. The partition key determines how data is distributed across partitions, impacting read and write throughput. The sort key enables efficient sorting and filtering. Choosing keys that align with access patterns minimizes data retrieval latency. For instance, if an application frequently queries data by user ID, user ID should be the partition key.
- Data Denormalization: Consider denormalizing data, particularly for read-heavy workloads. This involves duplicating data across multiple items to avoid expensive joins. For example, if a user profile requires frequent access to a list of recent activity, embedding the activity data directly within the user profile item can significantly reduce read latency compared to performing a separate query to another table.
- Item Size Optimization: DynamoDB has item size limits. Minimize the size of individual items to improve read and write performance. Avoid storing large attributes directly within items if possible. Consider storing large objects in Amazon S3 and storing a reference (e.g., an S3 object key) in DynamoDB.
- Batch Operations: Utilize batch operations (BatchGetItem and BatchWriteItem) to reduce the number of requests and improve throughput. Batch operations allow you to retrieve or write multiple items in a single request. For example, instead of issuing individual GetItem requests to retrieve multiple user profiles, use BatchGetItem to retrieve all profiles in one operation.
- Provisioned Throughput and Auto Scaling: Configure appropriate provisioned throughput for your tables or utilize auto-scaling. Under-provisioning can lead to throttling, while over-provisioning wastes resources. Auto scaling dynamically adjusts provisioned capacity based on actual traffic, optimizing both performance and cost.
- Use of Global Secondary Indexes (GSIs): Leverage GSIs to enable efficient queries on attributes other than the primary key. Design GSIs based on the application’s query requirements. GSIs replicate data from the base table, allowing for flexible querying.
Choosing Appropriate Data Types and Indexing Strategies
Selecting the right data types and indexing strategies is fundamental for optimizing DynamoDB performance. This choice affects storage efficiency, query performance, and overall application responsiveness.
- Data Type Selection: Choose data types that align with the data being stored. DynamoDB supports various data types, including strings, numbers, booleans, and lists. Using the correct data type optimizes storage and query performance. For example, use the NUMBER data type for numerical values to enable efficient numerical comparisons and aggregations.
- Indexing Strategies: Implement appropriate indexing strategies, primarily primary keys (partition key and sort key) and secondary indexes (GSIs and LSIs), based on query patterns. GSIs are useful for querying on attributes other than the primary key. Local Secondary Indexes (LSIs) are useful for queries within a specific partition. LSIs have limitations on the number and size.
- Consideration of Attribute Data Types: Use appropriate attribute data types. For example, if you are storing dates and times, consider using the STRING data type in the ISO 8601 format (e.g., “2023-10-27T10:00:00Z”) for easier sorting and filtering.
- Avoid Unnecessary Indexes: Create indexes only when needed. Each index adds storage and write overhead. Analyze query patterns and create indexes only for attributes that are frequently queried.
Monitoring DynamoDB Performance Metrics and Identifying Potential Bottlenecks
Monitoring DynamoDB performance is essential for identifying and resolving performance issues. AWS provides several metrics that can be used to track DynamoDB performance and pinpoint bottlenecks.
- Key Metrics: Monitor key metrics such as consumed read capacity units (RCUs), consumed write capacity units (WCUs), throttled requests, and latency. Consumed RCUs and WCUs indicate the amount of provisioned capacity being utilized. Throttled requests indicate capacity bottlenecks. Latency measures the time taken for read and write operations.
- Using Amazon CloudWatch: Utilize Amazon CloudWatch to monitor DynamoDB metrics. CloudWatch provides real-time dashboards and alerts. Set up alarms to be notified of throttling or high latency. Configure CloudWatch metrics to track read and write capacity utilization, request latencies, and error rates.
- Analyzing Throttling: Throttling indicates that your application is exceeding the provisioned capacity. Analyze throttled requests to determine the source of the bottleneck. Consider increasing provisioned capacity, optimizing data access patterns, or implementing auto-scaling to mitigate throttling.
- Identifying Hot Partitions: Hot partitions occur when a disproportionate amount of read or write traffic is directed to a single partition. Monitor the distribution of requests across partitions. If a single partition is consistently consuming a large portion of the provisioned capacity, consider redesigning the partition key or using GSIs to distribute the load more evenly.
- Analyzing Latency: High latency can indicate performance issues. Analyze the latency metrics for read and write operations. If latency is high, consider optimizing data modeling, increasing provisioned capacity, or improving data access patterns. Investigate whether queries are efficient and use indexes effectively.
- Performance Testing: Conduct performance testing to simulate real-world workloads and identify potential bottlenecks before deploying to production. Use tools like the AWS SDK for Java’s DynamoDBMapper or other performance testing frameworks to simulate read and write operations under varying loads. For example, you can simulate a sudden spike in traffic by increasing the number of concurrent users and observing the impact on DynamoDB metrics.
Implementing Scalable Serverless APIs with DynamoDB
Designing and deploying scalable serverless APIs is a critical aspect of modern application development. This section delves into constructing REST APIs using API Gateway and Lambda functions, all interacting with DynamoDB. It emphasizes handling pagination and filtering for efficient data retrieval and demonstrates how to integrate API Gateway with DynamoDB for scalable data access.
Designing a REST API with API Gateway and Lambda Functions for DynamoDB Interaction
Building a REST API involves defining endpoints, request methods, and data formats to facilitate communication between clients and the serverless backend. This section explores the architecture, focusing on API Gateway, Lambda functions, and DynamoDB interaction.
The architecture typically comprises the following components:
- API Gateway: Acts as the entry point for client requests. It handles routing, authentication, authorization, and request transformation. API Gateway receives incoming HTTP requests, forwards them to the appropriate Lambda functions, and returns responses to the clients.
- Lambda Functions: Serverless compute units that execute the business logic. Each function is responsible for a specific task, such as creating, reading, updating, or deleting data (CRUD operations) in DynamoDB. They are triggered by API Gateway events.
- DynamoDB: The NoSQL database that stores the application’s data. Lambda functions interact with DynamoDB to persist and retrieve data. DynamoDB provides high availability, scalability, and performance, essential for serverless applications.
The data flow proceeds as follows:
- A client sends an HTTP request to an API Gateway endpoint.
- API Gateway routes the request to the appropriate Lambda function based on the defined configuration (e.g., path, HTTP method).
- The Lambda function receives the request, processes it, and interacts with DynamoDB to perform the required operations (e.g., querying data, writing data).
- The Lambda function returns a response to API Gateway.
- API Gateway forwards the response to the client.
Consider an example for a ‘users’ resource:
- GET /users: Retrieves a list of users. This triggers a Lambda function that queries the ‘users’ table in DynamoDB.
- GET /users/userId: Retrieves a specific user by their ID. This triggers a Lambda function that queries the ‘users’ table using the userId as a key.
- POST /users: Creates a new user. This triggers a Lambda function that writes a new item to the ‘users’ table.
- PUT /users/userId: Updates an existing user. This triggers a Lambda function that updates an item in the ‘users’ table.
- DELETE /users/userId: Deletes a user. This triggers a Lambda function that deletes an item from the ‘users’ table.
Handling Pagination and Filtering in API Responses
Implementing pagination and filtering is crucial for managing large datasets and improving API performance. This section details strategies to provide clients with manageable chunks of data and the ability to refine search results.
Pagination involves dividing the data into pages, allowing clients to retrieve data in smaller, more manageable sets. Filtering enables clients to narrow down results based on specific criteria.
- Pagination Implementation:
- Using `Limit` and `Offset`: This is a simple approach where the client specifies the `limit` (number of items per page) and `offset` (starting point for the page). However, it can be inefficient for large datasets as the server may need to scan a large number of items to reach the offset.
- Using `ExclusiveStartKey`: DynamoDB provides `ExclusiveStartKey` for efficient pagination. After retrieving a page of results, the server returns a `LastEvaluatedKey` (or similar) representing the last item retrieved. The client uses this key in the next request as the `ExclusiveStartKey` to retrieve the subsequent page.
- Using Query and Scan Operations: The `Query` operation in DynamoDB is suitable for retrieving data based on a primary key or an index. The `Scan` operation can be used for filtering data based on any attribute, but it can be less efficient for large datasets as it scans the entire table.
- Using Indexing: Create secondary indexes on frequently filtered attributes. This allows for more efficient querying using the `Query` operation.
Example:
Consider a scenario where a client requests a list of products with pagination and filtering.
1. Pagination using `ExclusiveStartKey`:
The API endpoint is `/products`.
– First request: `/products?limit=10` (Retrieves the first 10 products). The server responds with the first 10 products and `LastEvaluatedKey`.
– Second request: `/products?limit=10&exclusiveStartKey=LastEvaluatedKey` (Retrieves the next 10 products). The server responds with the next 10 products and, potentially, another `LastEvaluatedKey`.
2. Filtering using Indexes:
The API endpoint is `/products?category=electronics`.
If a secondary index is created on the `category` attribute, the API can use the `Query` operation to efficiently retrieve products within the ‘electronics’ category. Without an index, a `Scan` operation would be necessary, potentially impacting performance.
Integrating API Gateway with DynamoDB for Scalable Data Access
This section examines how to directly integrate API Gateway with DynamoDB, bypassing Lambda functions for simple CRUD operations. This approach offers enhanced performance and reduces latency for specific use cases.
Direct integration is suitable for straightforward CRUD operations where minimal business logic is required. This integration enables API Gateway to interact directly with DynamoDB tables, reducing the number of components in the request flow and improving response times.
The configuration steps involve setting up the following:
- API Gateway Configuration: Define the API endpoints, HTTP methods (GET, POST, PUT, DELETE), and the corresponding request and response models.
- IAM Permissions: Configure the IAM role for API Gateway to grant it the necessary permissions to access the DynamoDB tables. This role must include permissions for actions like `dynamodb:GetItem`, `dynamodb:PutItem`, `dynamodb:UpdateItem`, and `dynamodb:DeleteItem`.
- Integration Requests and Responses: Configure the integration requests to map incoming API Gateway requests to DynamoDB operations. Define the request parameters (e.g., table name, key attributes) and response models to format the data returned from DynamoDB.
Example:
Consider a simplified scenario where a client needs to create a new user:
1. API Endpoint: `/users` (POST method).
2. Request Mapping:
– API Gateway receives the POST request with the user data in the request body.
– The integration request maps the request body to the `PutItem` operation in DynamoDB.
– The request parameters include the DynamoDB table name and the item attributes extracted from the request body.
3. Response Mapping:
– DynamoDB executes the `PutItem` operation.
– API Gateway receives the response from DynamoDB.
– The integration response maps the DynamoDB response (e.g., success or error) to the API Gateway response. The response might include the newly created user’s ID or an error message.
Direct integration can provide significant performance benefits in situations with high traffic or where the Lambda function’s overhead impacts performance. For instance, a content delivery network (CDN) that serves a large number of static assets could use direct integration to fetch metadata from DynamoDB without involving Lambda functions. This streamlines the process, reduces latency, and improves overall throughput.
Using DynamoDB Streams for Real-time Serverless Applications
DynamoDB Streams enable real-time data processing and event-driven architectures within serverless applications. This capability transforms DynamoDB from a simple data storage solution into a powerful component for building responsive and interactive applications. By capturing changes to DynamoDB tables, streams trigger downstream processes, allowing applications to react instantly to data modifications.
DynamoDB Streams: Concept and Role in Real-time Applications
DynamoDB Streams capture a time-ordered sequence of item-level changes made to a DynamoDB table. Each stream record represents a modification event, detailing the change (creation, update, or deletion) and providing the item’s attributes before and after the change (or just after for creations and before for deletions). This stream of events is then consumed by other AWS services, most commonly Lambda functions, to trigger actions in response to these data changes.
The fundamental role of DynamoDB Streams is to facilitate real-time data synchronization, event-driven processing, and the construction of reactive applications.
- Change Data Capture (CDC): DynamoDB Streams act as a CDC mechanism, recording every modification to a DynamoDB table. This enables applications to track data evolution over time.
- Event-Driven Architecture: They are the cornerstone of event-driven architectures, allowing components to react to changes without requiring constant polling or direct dependencies.
- Real-time Applications: DynamoDB Streams are critical for building real-time applications, such as chat applications, leaderboards, and applications that require immediate data updates.
- Data Replication and Synchronization: They facilitate data replication across different regions or data stores.
Using DynamoDB Streams with Lambda Functions for Event Processing
Integrating DynamoDB Streams with Lambda functions involves configuring the Lambda function as an event source for the stream. When changes occur in the DynamoDB table, the stream publishes these changes as events, and Lambda functions are invoked to process them. This process leverages the asynchronous nature of Lambda functions to handle events without blocking other operations.
The configuration process involves specifying the DynamoDB table’s stream as the event source within the Lambda function configuration. The Lambda function is triggered whenever new records appear in the stream. Each Lambda invocation receives a batch of stream records as input, allowing for efficient processing of multiple changes simultaneously.
- Event Source Mapping: The AWS Lambda service provides an event source mapping for DynamoDB Streams. This mapping handles polling the stream, batching records, and invoking the Lambda function.
- Batch Processing: Lambda functions typically receive a batch of stream records. The batch size can be configured to optimize performance and cost.
- Event Structure: Each event record contains information about the change, including the event type (INSERT, MODIFY, REMOVE), the table name, the keys of the modified item, and the item’s attributes before and after the change.
- Processing Logic: The Lambda function contains the business logic to process the stream records. This logic could involve updating related data, sending notifications, or triggering other actions.
Example: A social media application uses DynamoDB to store user posts. Whenever a new post is created (INSERT), the DynamoDB stream captures the event. A Lambda function, triggered by the stream, then updates a global feed to include the new post. Another example is a e-commerce application, where the stream records every time a product is updated. The lambda function is then in charge of updating the product in the search engine to be available immediately for users.
Handling Errors and Implementing Retry Mechanisms
Processing stream events with Lambda functions requires robust error handling and retry mechanisms. Transient errors (e.g., temporary network issues) and application-level errors (e.g., invalid data) need to be addressed to ensure data consistency and prevent data loss. Without appropriate error handling, a single processing failure can halt the processing of all subsequent records in the stream, potentially causing significant delays or data loss.
- Error Handling Strategies: Implement strategies to handle errors effectively. The common strategies are:
- Exception Handling: Use try-catch blocks within the Lambda function to catch exceptions and log errors.
- Dead-Letter Queues (DLQ): Configure a DLQ (e.g., an SQS queue) to store failed events for later inspection and reprocessing. This prevents errors from blocking the processing of other events.
- Monitoring and Alerting: Monitor Lambda function errors using CloudWatch metrics and set up alerts to notify administrators of processing failures.
- Retry Mechanisms: Implement retry mechanisms to handle transient errors.
- Lambda’s Built-in Retries: Lambda automatically retries function invocations in case of certain errors (e.g., throttling). Configure the retry attempts and exponential backoff settings.
- Custom Retries: Implement custom retry logic within the Lambda function for specific error scenarios. This could involve retrying the failed operation after a delay.
- Batch Processing Considerations: When processing batches of stream records, identify and handle individual record failures within the batch. Implement a mechanism to retry only the failed records.
- Idempotency: Design the Lambda function to be idempotent. Idempotency ensures that processing the same event multiple times has the same effect as processing it once. This is crucial to avoid unintended side effects when retries occur.
Example: A Lambda function attempts to update a related database when processing a stream record. If the database update fails due to a temporary network issue, the Lambda function retries the operation with an exponential backoff strategy. If the update continues to fail after multiple retries, the failed event is sent to a DLQ for further analysis and manual intervention.
This approach ensures that the event is not lost, and the system can eventually recover from the failure. Another example, when the application processes the event, it can check for existing data before inserting it to prevent duplicates in case of a retry.
Monitoring and Troubleshooting DynamoDB in Serverless Applications
Effective monitoring and troubleshooting are crucial for maintaining the performance, availability, and cost-efficiency of DynamoDB in serverless applications. This involves understanding key metrics, implementing robust logging and debugging strategies, and having a systematic approach to diagnose and resolve issues. Proactive monitoring helps identify potential problems before they impact users, allowing for timely intervention and optimization.
Essential DynamoDB Monitoring Metrics and Their Interpretation
Monitoring DynamoDB involves tracking several key metrics to understand its behavior and identify potential bottlenecks. Analyzing these metrics allows for informed decisions regarding resource allocation, query optimization, and overall application performance.
- Consumed Capacity Units (CCU): This metric reflects the actual resources DynamoDB is using to process read and write requests. It is measured in read capacity units (RCUs) and write capacity units (WCUs).
- Throttled Requests: This metric indicates the number of requests that were rejected because the application exceeded its provisioned capacity.
- Successful Request Latency: This metric measures the time it takes for DynamoDB to process successful requests.
- Provisioned Capacity vs. Consumed Capacity: Comparing provisioned and consumed capacity is critical for cost optimization.
- Conditional Check Failed Requests: This metric counts the number of requests that failed due to a conditional check not being met.
- User Errors: This metric reflects the number of requests that resulted in errors reported by the application, such as invalid parameters or access denied.
Interpreting CCU involves understanding how it relates to provisioned capacity. If CCU consistently exceeds provisioned capacity, throttling occurs, leading to increased latency and potential application failures. For example, a serverless application that provisioned 100 RCUs and experiences a sustained read traffic exceeding 100 RCUs will begin to experience throttling. AWS provides CloudWatch metrics to monitor these situations, alerting developers to scale up provisioned capacity or optimize read patterns (e.g., by using eventually consistent reads or caching).
High numbers of throttled requests signal a capacity issue. Analyzing the source of throttled requests (e.g., specific operations or table partitions) is critical for identifying the root cause. For instance, if a table receives a sudden spike in write requests, the WCUs might be exhausted, leading to throttling. AWS provides detailed metrics that can be used to correlate throttling with specific operations, such as `PutItem` or `UpdateItem`.
This information can be used to determine the need to scale up write capacity, optimize the request rate, or implement retry mechanisms.
Analyzing latency provides insights into query performance and potential performance bottlenecks. Elevated latency can be caused by a variety of factors, including inefficient queries, insufficient provisioned capacity, or hot partitions. For example, a poorly optimized query that scans a large table instead of using an index will have significantly higher latency than a query that uses an efficient index.
Monitoring this metric helps identify performance degradations and guides query optimization efforts.
If the application consistently consumes less capacity than provisioned, it indicates over-provisioning, which results in unnecessary costs. Conversely, if the application consistently consumes more capacity than provisioned, it indicates under-provisioning, which can lead to throttling and performance issues. For instance, if a table is provisioned with 1000 RCUs, but consistently consumes only 200 RCUs, the provisioned capacity should be reduced to save costs.
AWS offers auto-scaling capabilities to automatically adjust provisioned capacity based on actual traffic patterns, further optimizing costs.
Analyzing conditional check failures is essential for understanding data consistency issues. High numbers of conditional check failures can indicate conflicts in concurrent operations. For example, if two users attempt to update the same item simultaneously, and one of the updates is based on stale data, the conditional check will fail, ensuring data integrity. Monitoring this metric allows developers to identify and address data conflicts, such as by implementing optimistic locking mechanisms.
User errors indicate issues with the application’s interaction with DynamoDB. Monitoring user errors helps to identify problems related to data validation, incorrect API calls, or permission issues. For example, if an application attempts to write data to a table it does not have permission to access, a user error will occur. Analyzing user errors is important for debugging and improving the application’s interaction with DynamoDB.
Troubleshooting Steps for Common DynamoDB Access and Performance Issues
When troubleshooting DynamoDB issues, a systematic approach is crucial. This involves identifying the symptoms, analyzing the relevant metrics, and implementing corrective actions.
- Throttling: If the application experiences throttling, investigate the root cause.
- High Latency: Investigate the causes of high latency.
- Data Consistency Issues: If data consistency problems are observed, investigate the application’s data access patterns.
- Authentication and Authorization Issues: Verify that the application has the necessary permissions to access DynamoDB.
- Cost Optimization: Monitor the provisioned capacity versus the consumed capacity.
The initial step involves checking the `Throttled Requests` metric in CloudWatch. If throttling is present, examine the `Consumed Capacity Units` and compare them to the provisioned capacity. If the `Consumed Capacity Units` exceed the provisioned capacity, consider increasing the provisioned capacity, optimizing the query patterns (e.g., using eventually consistent reads, batch operations), or implementing a retry mechanism with exponential backoff.
For example, if a high volume of write requests is causing throttling, increasing the provisioned WCUs can resolve the issue. If the throttling is isolated to a specific partition, it may indicate a “hot partition” issue, which could be addressed by choosing a different partition key or using a more effective distribution strategy.
Analyze the `Successful Request Latency` metric to identify latency spikes. If the latency is high, examine the queries to see if they are efficient. Are the queries using appropriate indexes? Are they scanning entire tables when they should be using indexes? Use DynamoDB’s query profiler to analyze query performance.
Consider optimizing the data model to improve query efficiency. For instance, a query that scans a large table instead of using an index will have significantly higher latency.
Monitor the `Conditional Check Failed Requests` metric. High numbers of conditional check failures suggest potential conflicts. Review the application’s use of conditional writes and transactions. Implement appropriate locking mechanisms, if necessary, to ensure data integrity. For example, if multiple users are updating the same item concurrently, use optimistic locking with the `ConditionExpression` parameter in `UpdateItem` to prevent data loss.
Check for user errors related to access denied. Review the IAM roles and policies associated with the application’s execution environment (e.g., Lambda function). Ensure that the IAM policies grant the necessary permissions to perform the required DynamoDB operations. For example, a Lambda function that is attempting to read data from a DynamoDB table must have the `dynamodb:GetItem` permission on that table.
Regularly review the provisioned capacity for each table. If the application consistently consumes less capacity than provisioned, reduce the provisioned capacity to minimize costs. If the application consistently consumes more capacity than provisioned, consider increasing the provisioned capacity. Use AWS auto-scaling features to automatically adjust the provisioned capacity based on traffic patterns. For instance, if the application has predictable traffic patterns, use auto-scaling policies to increase capacity during peak hours and decrease capacity during off-peak hours.
Tools and Techniques for Logging and Debugging DynamoDB Interactions in Serverless Applications
Effective logging and debugging are essential for gaining visibility into DynamoDB interactions and diagnosing issues. Implementing a comprehensive logging strategy, combined with the right tools, significantly simplifies the troubleshooting process.
- CloudWatch Logs: Use CloudWatch Logs to capture detailed information about DynamoDB interactions.
- AWS X-Ray: Integrate AWS X-Ray to trace requests across multiple services.
- DynamoDB Query Profiler: Utilize the DynamoDB Query Profiler to analyze query performance.
- Local Development and Testing: Employ local development environments and testing frameworks to debug DynamoDB interactions.
- Error Handling and Retries: Implement robust error handling and retry mechanisms.
Log all DynamoDB operations, including the request parameters, response details, and any errors. Configure Lambda functions to log the DynamoDB requests and responses. This will provide a detailed audit trail of all interactions. For example, log the `TableName`, `OperationType`, `RequestItems`, and `ResponseMetadata` for each DynamoDB request. Use structured logging formats, such as JSON, to facilitate easier analysis and filtering of logs.
X-Ray provides a comprehensive view of how requests flow through the application, including DynamoDB interactions. Enable X-Ray tracing in Lambda functions and other services that interact with DynamoDB. This enables the identification of performance bottlenecks and dependencies. For example, if a Lambda function calls DynamoDB and then calls another service, X-Ray will show the time spent in each service, including the DynamoDB calls.
The DynamoDB Query Profiler helps to identify inefficient queries. It analyzes the query execution plan and provides insights into the cost of each operation. Use the profiler to optimize slow queries and reduce latency. For example, the query profiler will show if a query is scanning the entire table when it should be using an index.
Use the DynamoDB Local tool for local testing. This enables developers to test their applications without incurring costs. Use unit tests and integration tests to verify the correctness of DynamoDB operations. For example, write unit tests to verify that the application correctly handles different data types and edge cases.
Handle DynamoDB errors gracefully and implement retry logic with exponential backoff. This helps to mitigate transient errors and improve the application’s resilience. For example, if a `ProvisionedThroughputExceededException` is received, implement a retry mechanism with exponential backoff.
Advanced DynamoDB Features and Serverless Integration
DynamoDB, a fully managed NoSQL database service, offers several advanced features that significantly enhance the capabilities of serverless applications. These features are crucial for building highly available, scalable, and performant applications. This section delves into Global Tables for multi-region deployments and DynamoDB Accelerator (DAX) for improved read performance, providing insights into their design, implementation, and benefits.
Global Tables for Multi-Region Serverless Applications
Global Tables in DynamoDB enable the replication of data across multiple AWS Regions, providing low-latency access to data for users worldwide and ensuring high availability. This is particularly beneficial for serverless applications with a global user base or those requiring disaster recovery capabilities.To understand the benefits of Global Tables, consider the following aspects:
- Data Replication: Global Tables automatically replicate data between regions in near real-time. This means that updates made in one region are propagated to all other regions within seconds. This is achieved through DynamoDB’s underlying infrastructure and is managed without requiring manual intervention.
- Read Performance: By replicating data closer to users, Global Tables significantly reduce read latency. Users in different geographical locations can access data from a local region, resulting in faster response times. This is especially crucial for serverless applications that rely on rapid data retrieval.
- High Availability and Disaster Recovery: Global Tables provide built-in disaster recovery capabilities. If one region becomes unavailable, the application can automatically fail over to another region, ensuring continuous availability. This redundancy is a critical feature for mission-critical serverless applications.
- Conflict Resolution: DynamoDB Global Tables handle conflicts that may arise from concurrent updates in different regions using the “last writer wins” strategy by default. However, custom conflict resolution strategies can be implemented for more complex scenarios.
- Implementation: Setting up Global Tables involves creating a DynamoDB table in a primary region and then adding replicas in other regions. DynamoDB handles the data synchronization and replication automatically.
For example, a global e-commerce platform could use Global Tables to store product catalogs and user profiles. Users in North America, Europe, and Asia would access the data from their respective regional replicas, resulting in improved performance and resilience.
DynamoDB Accelerator (DAX) to Improve Read Performance
DynamoDB Accelerator (DAX) is an in-memory cache that significantly improves read performance for DynamoDB tables. DAX is designed to be a fully managed, highly available, and scalable cache, minimizing the latency of read operations and reducing the load on DynamoDB tables.The following points explain the design strategy for using DAX:
- Caching Strategy: DAX caches frequently accessed data in memory. When a read request is made, DAX first checks its cache. If the data is found (a “cache hit”), it returns the data immediately. If the data is not found (a “cache miss”), DAX retrieves the data from DynamoDB, caches it, and then returns it to the client.
- Deployment: DAX is deployed as a cluster of nodes within a VPC (Virtual Private Cloud). The number of nodes can be scaled up or down to meet the application’s performance requirements. DAX is designed to be highly available and automatically handles node failures.
- Integration: Integrating DAX with an application is straightforward. Applications use the DAX client SDK, which acts as a proxy between the application and DynamoDB. The DAX client automatically handles cache lookups and updates.
- Use Cases: DAX is particularly effective for read-heavy workloads, such as applications that frequently retrieve the same data. It is well-suited for applications like social media feeds, product catalogs, and content management systems.
- Invalidation: DAX automatically invalidates cached data when the underlying data in DynamoDB is updated. This ensures that the cache always contains the most up-to-date information.
Consider a social media application. Users frequently read posts, comments, and user profiles. By using DAX, the application can significantly reduce the latency of these read operations, improving the user experience and reducing the load on the DynamoDB tables.
Comparison of DynamoDB Accelerator (DAX) Advantages and Disadvantages
The following table Artikels the advantages and disadvantages of DynamoDB Accelerator (DAX) in a four-column format:
| Feature | Advantages | Disadvantages | Considerations |
|---|---|---|---|
| Performance | Significantly reduces read latency, often by orders of magnitude. Improves read throughput. | Adds an additional layer of infrastructure to manage. Introduces potential for cache misses. | Evaluate the read-to-write ratio of your workload. DAX is most effective for read-heavy applications. |
| Cost | Can reduce the cost of DynamoDB reads by offloading read traffic. | DAX itself has associated costs based on instance size and usage. | Compare the cost savings from reduced DynamoDB read units (RCUs) with the cost of DAX. |
| Complexity | Easy to integrate with existing DynamoDB applications using the DAX client SDK. Fully managed, reducing operational overhead. | Adds complexity to the overall architecture. Requires monitoring and management of the DAX cluster. | Ensure your team has the necessary expertise to manage and monitor DAX. |
| Data Consistency | Provides eventual consistency. Updates to DynamoDB are eventually reflected in the DAX cache. | Data might not be immediately consistent between DynamoDB and DAX. | Consider the data consistency requirements of your application. DAX is generally suitable for data that does not require immediate consistency. Implement strategies for invalidating or refreshing cache entries. |
Concluding Remarks
In conclusion, mastering the art of how to use Amazon DynamoDB for serverless applications empowers developers to construct highly scalable, resilient, and cost-effective systems. From fundamental table creation to advanced features like Global Tables and DAX, DynamoDB provides a versatile toolkit for managing data in a serverless environment. By adhering to best practices in security, performance optimization, and real-time data processing, developers can unlock the full potential of DynamoDB, ensuring that their serverless applications remain robust, efficient, and adaptable to evolving business requirements.
This guide serves as a foundation for building sophisticated serverless applications that leverage the power of DynamoDB.
FAQ Resource
What are the key advantages of using DynamoDB over traditional relational databases in serverless applications?
DynamoDB offers several advantages: automatic scaling, eliminating the need for capacity planning; pay-per-use pricing, reducing costs; high availability and fault tolerance; and seamless integration with other AWS services, simplifying development and deployment.
How does DynamoDB handle data consistency, and what consistency models are available?
DynamoDB supports two consistency models: eventually consistent reads, which offer high performance but may return stale data, and strongly consistent reads, which guarantee the most up-to-date data at the cost of higher latency and potential throttling.
What is the best practice for handling database connections within AWS Lambda functions when using DynamoDB?
Establish and reuse database connections outside the Lambda function handler to avoid the overhead of creating new connections for each invocation. This can be achieved by initializing the DynamoDB client outside the handler or using connection pooling techniques.
How can I monitor the performance of my DynamoDB tables in a serverless environment?
Utilize Amazon CloudWatch to monitor key DynamoDB metrics, including consumed read/write capacity units, latency, throttled requests, and error rates. Setting up alarms based on these metrics helps proactively identify and address performance bottlenecks.
What is the purpose of DynamoDB Streams, and how can they be used in serverless applications?
DynamoDB Streams provide a time-ordered sequence of changes made to a DynamoDB table. They are used to trigger real-time event processing, such as updating related data, triggering notifications, or building real-time analytics, by integrating with Lambda functions or other AWS services.