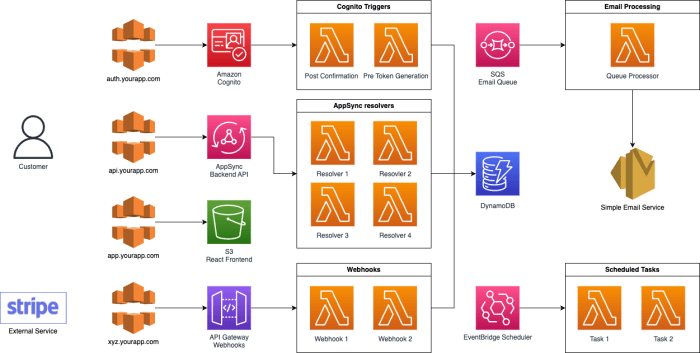
Embarking on the journey of how to implement blue-green deployments for Lambda functions is a crucial step in modern serverless architecture. This approach, a cornerstone of continuous delivery, promises zero downtime and streamlined rollbacks, enhancing application resilience and user experience. However, successful implementation demands a deep understanding of its components, from function versioning and alias management to the orchestration of traffic shifting and rigorous testing strategies.
This guide delves into the intricacies of blue-green deployments for Lambda, providing a structured approach from initial planning to advanced strategies. It navigates through essential prerequisites, deployment configurations, and robust testing protocols. Furthermore, it explores critical aspects like monitoring, security, and troubleshooting, ensuring a comprehensive understanding of the entire lifecycle, making this guide a critical asset for developers and DevOps engineers seeking to optimize their Lambda deployments.
Introduction to Blue-Green Deployments for Lambda
Blue-green deployments represent a strategic approach to software deployment, especially beneficial in environments like AWS Lambda, where the agility of serverless functions is paramount. This method involves maintaining two identical environments, designated “blue” and “green,” with only one actively serving production traffic at any given time. The inactive environment is prepared with the new version of the application, and a switchover redirects traffic to the updated environment.
This process minimizes disruption and provides a straightforward rollback strategy.This approach offers distinct advantages in the context of serverless architectures. It provides a mechanism for zero-downtime deployments, enabling continuous updates without service interruption. The ability to swiftly revert to the previous version in case of issues enhances system stability and reduces the risk associated with introducing new code.
Core Concept of Blue-Green Deployments in Serverless Functions
The fundamental principle revolves around maintaining two identical copies of a Lambda function, along with the necessary infrastructure to support them. One environment, the “blue” environment, handles all live production traffic. The “green” environment, in contrast, remains inactive, housing the new version of the Lambda function ready for deployment. The deployment process involves deploying the new function version to the green environment, performing tests, and finally, switching the traffic routing from blue to green.
Advantages of Using Blue-Green Deployments with Lambda Functions
Blue-green deployments provide several key benefits that improve the resilience and maintainability of Lambda-based applications. These advantages are crucial for ensuring a smooth user experience and efficient development cycles.
- Zero Downtime Deployments: The primary advantage is the ability to deploy new code without any interruption in service. Traffic is seamlessly switched from the blue environment to the green environment after the green environment is fully tested and ready. This minimizes any potential impact on end-users and ensures continuous availability.
- Rollback Capabilities: If the new version deployed to the green environment encounters any issues, a rapid rollback to the blue environment is easily achieved. This minimizes the impact of bugs or performance degradation in the new version. The ability to quickly revert to a stable state is a significant advantage in managing software releases.
- Reduced Risk: Blue-green deployments reduce the risk associated with deployments. By testing the new version in a production-like environment before directing live traffic, potential problems are identified and addressed before they impact users.
- Simplified Testing: The green environment can be used for comprehensive testing before the switchover. This includes unit tests, integration tests, and performance tests, ensuring the new version is stable and meets performance requirements.
- Improved Maintainability: Blue-green deployments simplify the maintenance process. Updates can be deployed and tested in a controlled environment, minimizing the risk of errors and downtime. This contributes to a more robust and reliable system.
Potential Drawbacks of Blue-Green Deployments for Lambda and Mitigation Strategies
While blue-green deployments offer significant advantages, certain considerations must be addressed to ensure their effective implementation. These potential drawbacks and their mitigation strategies are critical for maximizing the benefits of this deployment strategy.
- Increased Infrastructure Costs: Maintaining two identical environments can increase infrastructure costs, as resources are duplicated.
- Mitigation: Implement auto-scaling and resource optimization to minimize the cost of the inactive environment. Consider using a cost-effective approach for the inactive green environment, scaling down resources when not in use.
- Complexity in Infrastructure: Setting up and managing the infrastructure required for blue-green deployments can be more complex than simpler deployment strategies. This involves managing routing, DNS configurations, and testing procedures.
- Mitigation: Use Infrastructure as Code (IaC) tools, such as AWS CloudFormation or Terraform, to automate the setup and management of the infrastructure. These tools allow you to define the infrastructure in code, making it easier to replicate, update, and manage.
- Data Synchronization: If the Lambda function interacts with a database or other stateful services, data synchronization between the blue and green environments becomes crucial. Any data changes during testing must be carefully managed to prevent data inconsistencies.
- Mitigation: Implement a strategy for data synchronization, such as database replication or a data migration process. Employ techniques like feature flags to control the release of new features and prevent data inconsistencies.
- Testing Complexity: Comprehensive testing of the green environment is crucial before the switchover. This can be time-consuming and require careful planning.
- Mitigation: Automate testing processes as much as possible. Use automated testing tools and integrate testing into the deployment pipeline. Implement canary deployments as an initial phase to test the new version with a small percentage of traffic.
- Routing and DNS Management: Managing traffic routing and DNS configurations to switch between the blue and green environments requires careful planning.
- Mitigation: Use a service like AWS Route 53 or an API Gateway to manage traffic routing. Automate the process of switching traffic between the blue and green environments to minimize manual intervention.
Prerequisites and Planning
Implementing blue-green deployments for AWS Lambda functions necessitates careful planning and the utilization of specific AWS services and tools. This section details the essential components and Artikels a strategic approach to ensure a smooth and reliable deployment process, focusing on minimizing downtime and facilitating rollback capabilities.
Required AWS Services and Tools
The successful execution of blue-green deployments for Lambda relies on a suite of AWS services working in concert. These services provide the necessary infrastructure for traffic management, versioning, and deployment automation.
- AWS Lambda: This is the core service where your functions reside. Lambda provides the execution environment and supports function versioning. Each version represents a specific code snapshot.
- AWS CodeDeploy: CodeDeploy is a deployment service that automates the deployment of code to various compute services, including Lambda. It enables controlled deployments and provides features for monitoring and rollback. CodeDeploy facilitates the traffic shifting between blue and green versions.
- AWS Lambda Aliases: Aliases are pointers to specific Lambda function versions. They are crucial for traffic management. You can route traffic to an alias, and the alias, in turn, points to a specific function version. This abstraction allows for seamless traffic shifting without modifying the client-facing endpoint.
- AWS CloudWatch: CloudWatch is used for monitoring the performance of your Lambda functions. It provides metrics and logs that are essential for observing the behavior of your functions during and after deployment. These metrics help to identify potential issues and validate the success of the deployment.
- AWS Identity and Access Management (IAM): IAM is essential for managing permissions. Your Lambda functions, CodeDeploy deployments, and other related services require specific IAM roles and policies to interact with each other and other AWS resources. Properly configured IAM permissions are critical for the security and proper functioning of the deployment pipeline.
- AWS CloudFormation (Optional but Recommended): CloudFormation allows you to define your infrastructure as code. Using CloudFormation to define your Lambda functions, aliases, and CodeDeploy deployments ensures infrastructure consistency and enables repeatable deployments. It facilitates the creation and management of all the necessary resources in a standardized manner.
Deployment Strategy and Traffic Management
A well-defined deployment strategy is paramount for the success of blue-green deployments. This strategy must incorporate mechanisms for traffic management, version control, and monitoring.
- Function Versioning: Each deployment should create a new version of the Lambda function. This ensures that the “green” environment contains the latest code. The “blue” environment will continue to run the previous version. Versioning also enables easy rollback to a known good state.
- Alias Management: Employing aliases to manage traffic flow is crucial. The primary alias, such as “prod,” initially points to the “blue” version. During deployment, CodeDeploy updates the “prod” alias to point to the “green” version after the green version has been validated.
- Traffic Shifting: CodeDeploy facilitates traffic shifting. Initially, 100% of traffic is routed to the “blue” version. During the deployment, CodeDeploy shifts traffic gradually or instantaneously to the “green” version, based on the chosen deployment configuration. For example, a canary deployment shifts a small percentage of traffic to the “green” version first, allowing for early detection of issues.
- Deployment Configuration: CodeDeploy offers various deployment configurations, including:
- Canary Deployment: A small percentage of traffic is routed to the new version initially, allowing for validation before a full rollout. This helps identify and mitigate potential issues. For example, 10% of traffic might be routed to the “green” version initially.
- Linear Deployment: Traffic is shifted in equal increments over a specified period. This provides a more gradual transition.
- All-at-once Deployment: All traffic is shifted to the new version immediately. This is the fastest option but offers the least opportunity for error detection.
- Monitoring and Validation: Implement thorough monitoring using CloudWatch metrics and logs to validate the performance of the “green” version. Monitor metrics like invocation count, error rate, and latency. CodeDeploy can automatically roll back the deployment if certain error thresholds are exceeded.
Function Versioning and Alias Management Plan
Effective function versioning and alias management are critical for facilitating rollbacks and canary releases, ensuring system stability and minimizing disruptions.
- Version Creation: Every code update results in a new Lambda function version. These versions are immutable, preserving the state of the code at a specific point in time.
- Alias Assignment: The “prod” alias should be the primary entry point for production traffic. The “green” alias can be used for staging and testing the new version before it’s deployed to production.
- Rollback Strategy: In the event of an issue, quickly revert the “prod” alias to the previous, known-good version. This minimizes the impact of the problem. This is easily achieved because the old version remains active.
- Canary Release Implementation:
- Deploy the new function version to a new alias, such as “canary”.
- Use CodeDeploy to shift a small percentage of traffic from “prod” to “canary”.
- Monitor the “canary” version for errors and performance issues using CloudWatch.
- If no issues are detected, shift the remaining traffic from “prod” to the “canary” version. If issues are detected, roll back by shifting traffic back to the original “prod” version.
- Automated Rollback: CodeDeploy can be configured to automatically roll back the deployment if performance metrics fall outside predefined thresholds. This provides an automated safety net.
- Naming Conventions: Implement a clear naming convention for versions and aliases to improve manageability and reduce confusion. For example, use version numbers like `$LATEST`, `$VERSION`, and meaningful alias names like “prod”, “staging”, and “canary”.
Setting up the Blue and Green Environments
Establishing the blue and green environments is a critical step in implementing blue-green deployments for Lambda functions. This involves creating and configuring distinct versions of the Lambda function, along with the necessary infrastructure to manage traffic routing and ensure a seamless transition between the environments. The goal is to minimize downtime and risks during deployments by allowing for thorough testing and validation before the green environment takes over production traffic.
Configuring Lambda Function Versions (Blue and Green)
Creating distinct Lambda function versions (blue and green) involves defining separate codebases and configurations for each environment. This separation is fundamental to the blue-green deployment strategy, allowing for independent testing and rollbacks.To achieve this, follow these steps:
- Codebase Separation: Maintain two distinct codebases or branches in your version control system (e.g., Git) – one for the blue environment and one for the green environment. Each codebase should contain the source code for the respective function version. The separation allows for independent development and updates.
- Configuration Differences: Each function version should have its own configuration, including:
- Environment Variables: Use environment variables to configure settings specific to each environment, such as database connection strings, API endpoints, and feature flags. This allows for easy differentiation between the blue and green environments without modifying the code.
- Memory and Timeout: Configure the memory allocation and timeout settings based on the expected workload for each environment. This can be particularly useful for performance testing in the green environment before the switch.
- Concurrency Limits: Set concurrency limits to control the number of concurrent function invocations. This helps manage resource utilization and prevent overloading the function.
- Function Creation and Versioning:
- Blue Function: Create a Lambda function (e.g., `my-function-blue`) and deploy the blue codebase to it. Publish a version of this function (e.g., version 1).
- Green Function: Create a separate Lambda function (e.g., `my-function-green`) and deploy the green codebase to it. Publish a version of this function (e.g., version 1).
- Deployment Packages: Ensure the deployment packages for each function version contain all necessary dependencies. Utilize package managers like npm (for Node.js), pip (for Python), or Maven (for Java) to manage dependencies and create deployment packages that include all required libraries.
Creating and Configuring Lambda Aliases
Lambda aliases provide a mechanism to manage traffic routing between different function versions. Aliases are pointers to specific function versions, enabling controlled traffic shifting and facilitating rollback procedures.To effectively utilize aliases, consider the following:
- Alias Creation: Create two aliases:
- Production Alias (e.g., `prod`): This alias points to the currently active function version serving production traffic (initially, the blue version).
- Testing Alias (e.g., `test` or `staging`): This alias points to the green function version, enabling testing and validation before the deployment.
- Alias Configuration:
- Production Alias Routing: Initially, the `prod` alias points to the blue function version (e.g., `my-function-blue:1`). This ensures that production traffic is directed to the stable blue environment.
- Testing Alias Routing: The `test` alias points to the green function version (e.g., `my-function-green:1`). This allows testing of the new version without impacting production traffic.
- Traffic Shifting (during deployment): Use weighted routing (e.g., using AWS Lambda’s traffic shifting capabilities or a load balancer) to gradually shift traffic from the blue version to the green version through the `prod` alias. This can be done in stages (e.g., 10% to the green, then 50%, then 100%) to minimize the impact of any potential issues.
- Rollback Strategy: If any issues are detected during the green deployment, immediately revert the `prod` alias back to the blue function version. This restores the previous stable state.
- Monitoring and Observability: Implement comprehensive monitoring and logging for both the blue and green function versions. Use metrics like invocation count, error rate, latency, and memory usage to assess the performance and health of each version. This data informs decisions about traffic shifting and rollback procedures.
Setting up IAM Roles and Permissions
Properly configured IAM roles and permissions are crucial for ensuring the security and operational integrity of the blue-green deployment process. These roles define the actions the Lambda functions and deployment processes can perform.To establish the necessary IAM roles and permissions, follow this procedure:
- Lambda Execution Role:
- Purpose: This role grants the Lambda functions permission to execute and access AWS resources.
- Permissions:
- `lambda:InvokeFunction`: Allows the function to invoke other Lambda functions.
- `logs:CreateLogGroup`, `logs:CreateLogStream`, `logs:PutLogEvents`: Permits logging of function execution events to CloudWatch Logs.
- `s3:GetObject`, `s3:PutObject` (if the function interacts with S3): Allows the function to read and write objects in Amazon S3.
- Permissions to access any other AWS services that the function uses (e.g., DynamoDB, API Gateway).
- Assignment: Assign this role to both the blue and green Lambda functions.
- Deployment Role (for automated deployments):
- Purpose: This role is used by the deployment process (e.g., a CI/CD pipeline) to manage Lambda function versions and aliases.
- Permissions:
- `lambda:CreateFunction`, `lambda:UpdateFunctionCode`, `lambda:UpdateFunctionConfiguration`: Allows the deployment process to create, update, and configure Lambda functions.
- `lambda:PublishVersion`: Permits publishing new versions of Lambda functions.
- `lambda:CreateAlias`, `lambda:UpdateAlias`, `lambda:GetAlias`: Allows the deployment process to manage Lambda aliases.
- `iam:PassRole`: Permits the deployment process to pass the Lambda execution role to the Lambda functions.
- `s3:GetObject` (if the deployment process retrieves deployment packages from S3): Allows the deployment process to read deployment packages from Amazon S3.
- Assignment: This role should be assigned to the CI/CD service or the user performing the deployment.
- Security Best Practices:
- Least Privilege: Grant only the minimum necessary permissions to each role. Avoid overly permissive policies.
- Role Isolation: Separate roles for different functions or environments to minimize the impact of security breaches.
- Regular Auditing: Regularly review IAM policies and permissions to ensure they are up-to-date and secure.
Implementing Traffic Shifting with CodeDeploy
AWS CodeDeploy provides a robust and automated mechanism for orchestrating traffic shifting between the blue and green Lambda function versions. This process ensures minimal downtime during deployments and facilitates a smooth transition for users. Utilizing CodeDeploy streamlines the deployment process, offering features such as automated rollback capabilities and the ability to manage traffic distribution strategies.
Configuring CodeDeploy for Lambda Functions
Setting up CodeDeploy for Lambda functions involves several key steps. These steps ensure proper deployment and traffic management.
- Creating a CodeDeploy Application: An application in CodeDeploy serves as a container for related deployments. This organizes and manages the deployment process.
- Creating a Deployment Group: A deployment group specifies the target Lambda function, the deployment configuration, and the traffic-shifting strategy. This group dictates how CodeDeploy interacts with the Lambda function versions.
- Specifying the Lambda Function: The deployment group needs to be associated with the target Lambda function. This ensures that CodeDeploy knows which function to manage.
- Defining Deployment Configuration: The deployment configuration determines the deployment behavior, including the number of instances deployed at once and the rollback strategy. For Lambda, this configuration controls how traffic is shifted between versions.
- Configuring Deployment Hooks: Deployment hooks are Lambda functions that execute at various stages of the deployment process, such as before the traffic shift or after the validation. These hooks enable pre- and post-deployment tasks.
Deployment Configurations and Traffic-Shifting Strategies
CodeDeploy offers various deployment configurations to implement different traffic-shifting strategies. These configurations enable control over the transition process, allowing for flexible deployments.
- Immediate Switch: This strategy directs all traffic to the green environment immediately after the deployment. This approach minimizes downtime but increases the risk of impacting users if the green version has issues. The configuration would involve a single step, where CodeDeploy updates the alias associated with the function to point to the new green version.
- Canary Deployment (Gradual Shift): This strategy gradually shifts traffic from the blue to the green environment. It typically starts by routing a small percentage of traffic to the green version and progressively increases it. This approach allows for testing the green version with a limited user base before a full rollout. This configuration often involves a series of steps. For example, CodeDeploy might first shift 10% of the traffic, then 20%, 50%, and finally 100%, with each step potentially having validation hooks to ensure the green version is performing correctly.
- Linear Deployment (Gradual Shift with fixed increments): Similar to canary deployments, linear deployments shift traffic gradually. However, the shift happens in fixed increments over a specific time. This strategy provides a more controlled rollout. CodeDeploy shifts traffic in fixed increments, for example, 10% every 5 minutes, until all traffic is routed to the green version.
- All-at-Once Deployment: This deployment strategy immediately switches all traffic to the new Lambda function version. It offers the fastest deployment time but carries the highest risk. It is suitable for environments where downtime is critical or when the deployment is considered low-risk.
Example of a Canary Deployment using CodeDeploy:
Consider a scenario where a Lambda function handles user authentication. The blue version (version 1) is currently serving all traffic. The green version (version 2) is the new deployment. CodeDeploy is configured with the following steps:
- Pre-Traffic Hook: A Lambda function (e.g., `preTrafficHook`) is invoked to perform preliminary checks, such as validating the configuration or ensuring dependencies are available.
- Traffic Shifting: CodeDeploy shifts 10% of the traffic to version 2.
- Validation: A Lambda function (e.g., `validateTraffic`) is invoked to monitor version 2. This function checks for errors, performance metrics, and other relevant indicators.
- Traffic Shifting: If the validation passes, CodeDeploy shifts another 20% of the traffic to version 2.
- Validation: The `validateTraffic` function is invoked again.
- Traffic Shifting: If the validation continues to pass, CodeDeploy gradually shifts traffic to version 2 in increments (e.g., 30%, 40%), until 100% of the traffic is directed to the green version.
- Post-Traffic Hook: A Lambda function (e.g., `postTrafficHook`) is invoked to perform cleanup tasks, such as removing old resources or updating monitoring dashboards.
If any validation step fails, CodeDeploy can automatically roll back to the blue version, ensuring minimal impact on users. This strategy offers a safe and controlled deployment process.
Testing and Validation
Ensuring the reliability and stability of a blue-green deployment strategy hinges on robust testing and validation procedures. Thorough testing is crucial before shifting traffic to the green environment. This section Artikels a comprehensive approach to testing, encompassing strategy design, automated test implementation, and performance monitoring, to mitigate risks and guarantee a seamless transition.
Designing a Testing Strategy for the Green Deployment
A well-defined testing strategy is paramount to validating the green deployment. This strategy should cover various aspects of the application to identify potential issues before impacting users.The testing strategy should encompass several key areas:
- Functional Testing: This verifies that the application’s core functionalities operate as expected. It should cover all critical user flows and features. This includes testing different input scenarios and validating the outputs against expected results. For example, in an e-commerce application, functional tests would ensure that users can add items to their cart, proceed to checkout, and complete a purchase successfully.
- Performance Testing: This assesses the green environment’s performance under various load conditions. Performance tests will simulate realistic user traffic to evaluate response times, throughput, and resource utilization. This involves load testing, stress testing, and spike testing to identify bottlenecks and ensure the system can handle peak loads without degradation. For example, performance tests can simulate thousands of concurrent users accessing an API endpoint to assess response times and server resource consumption.
- Integration Testing: This verifies the interactions between the Lambda function and other dependent services, such as databases, APIs, and external systems. Integration tests will confirm that data is correctly passed between services and that the system as a whole functions as intended. For example, this would involve testing that a Lambda function correctly writes data to a database and that the database is accessible and responding as expected.
- Security Testing: This evaluates the security posture of the green deployment. Security tests will identify vulnerabilities and ensure that security controls are properly implemented. This includes penetration testing, vulnerability scanning, and access control validation. For example, a security test would check for common vulnerabilities like SQL injection or cross-site scripting.
- User Acceptance Testing (UAT): This involves end-users testing the green deployment to ensure it meets their requirements and expectations. UAT provides real-world feedback on usability and functionality. UAT can involve a limited set of users who can provide feedback on the new deployment before it goes live.
The testing strategy should define clear success criteria for each test type. The criteria might include acceptable response times, successful completion rates, and security vulnerability thresholds.
Implementing Automated Tests for Functionality and Performance
Automated tests are crucial for efficient and reliable validation of the green deployment. They allow for rapid feedback and can be integrated into the deployment pipeline.Implementing automated tests involves:
- Selecting Testing Tools: Choose appropriate testing tools based on the application’s technology stack and testing requirements. For Lambda functions, tools like Jest, Mocha, and Pytest can be used for unit and integration tests. Performance testing tools such as JMeter, Gatling, and Locust can be used to simulate load and measure performance.
- Writing Unit Tests: Unit tests focus on individual components or functions within the Lambda function. They should be designed to isolate and test specific logic, ensuring that each component functions correctly. For example, if a Lambda function processes a specific type of event, unit tests would verify that the function correctly parses the event data, performs the required operations, and returns the expected results.
- Creating Integration Tests: Integration tests verify the interactions between the Lambda function and other services. These tests should simulate real-world scenarios to ensure that the Lambda function can communicate with databases, APIs, and other external systems. For example, integration tests might verify that a Lambda function can successfully read data from a database and write data to another service.
- Developing Performance Tests: Performance tests should be designed to simulate realistic user traffic and measure the green environment’s performance. These tests can be used to assess response times, throughput, and resource utilization. For example, performance tests might simulate a high volume of concurrent requests to an API endpoint to measure the response time and server resource consumption under heavy load.
- Integrating Tests into the Deployment Pipeline: Automated tests should be integrated into the deployment pipeline to run automatically whenever a new version of the Lambda function is deployed. This ensures that the green deployment is thoroughly tested before traffic is shifted. For example, the deployment pipeline can be configured to automatically run unit tests, integration tests, and performance tests after the green environment is deployed.
Tests should be designed to provide detailed reports and metrics, which are essential for diagnosing issues and identifying areas for improvement.
Monitoring Performance and Health of Blue and Green Environments
Continuous monitoring is critical for maintaining the health and performance of both blue and green environments during and after deployment. This involves tracking key metrics and setting up alerts to identify and address issues proactively.Effective monitoring requires:
- Defining Key Metrics: Identify and track key performance indicators (KPIs) that reflect the health and performance of the application. Examples include:
- Latency: The time it takes for the application to respond to a request.
- Error Rates: The percentage of requests that result in errors.
- Throughput: The number of requests processed per unit of time.
- Resource Utilization: The utilization of CPU, memory, and other resources.
- Implementing Monitoring Tools: Utilize monitoring tools to collect, analyze, and visualize metrics. AWS CloudWatch, Datadog, and New Relic are examples of popular tools for monitoring Lambda functions and related resources.
- Setting up Alerts: Configure alerts to notify teams when metrics exceed predefined thresholds. Alerts should be triggered for critical issues such as high error rates or excessive latency.
- Comparing Blue and Green Environment Metrics: Compare the performance of the blue and green environments side-by-side. This helps to identify performance regressions and ensure that the green deployment is performing as expected.
- Analyzing Logs: Centralize and analyze logs from both environments to diagnose issues and identify root causes. AWS CloudWatch Logs and other log aggregation services can be used to collect and analyze logs.
By continuously monitoring the blue and green environments, teams can proactively identify and address issues, ensuring a smooth and reliable deployment process. The data gathered from monitoring provides valuable insights for optimizing the application’s performance and resource utilization.
Performing the Deployment
Initiating a blue-green deployment with CodeDeploy is a critical step, transforming the carefully constructed infrastructure into a live, updated service. This process involves triggering the deployment, monitoring its progress, and finally, transitioning live traffic to the new green environment. The successful execution hinges on meticulous attention to detail and a robust monitoring strategy to mitigate potential risks.
Initiating the Deployment with CodeDeploy
The deployment process with CodeDeploy is initiated through a series of actions, primarily involving the CodeDeploy service and associated AWS resources. These steps are designed to automate the process, minimizing manual intervention and reducing the potential for human error.To initiate a blue-green deployment, the following steps are typically undertaken:
- Create a Deployment: CodeDeploy deployments are initiated by creating a new deployment. This can be done through the AWS Management Console, the AWS CLI, or through infrastructure-as-code tools like Terraform or CloudFormation. The deployment is targeted to the CodeDeploy application and deployment group previously configured for the blue-green deployment strategy.
- Specify the Deployment Configuration: The deployment configuration defines the parameters for the deployment process, including the desired deployment strategy (e.g., `CodeDeployDefault.OneAtATime`), the number of instances to deploy to at once, and the success criteria for the deployment.
- Provide the Application Revision: The application revision, which contains the updated Lambda function code and any associated resources, is uploaded to an Amazon S3 bucket or other supported storage locations. CodeDeploy then downloads this revision to the specified resources.
- CodeDeploy Execution: CodeDeploy then orchestrates the deployment based on the deployment configuration and application revision. This typically involves the following:
- CodeDeploy creates a new version of the Lambda function, based on the application revision, within the green environment.
- CodeDeploy runs lifecycle hooks, if configured, such as pre-traffic and post-traffic hooks, which can be used to perform validation and testing before and after traffic shifting.
- CodeDeploy updates the alias or traffic routing configuration to shift traffic from the blue environment to the green environment (this is the final step of deployment).
- Deployment Verification: CodeDeploy verifies the successful deployment based on the criteria defined in the deployment configuration, which may include health checks and other validation steps.
- Deployment Completion: Once the deployment is complete and the green environment is serving traffic, CodeDeploy marks the deployment as successful or failed, based on the outcome of the verification steps.
Monitoring the Deployment Process
Continuous monitoring is crucial throughout the deployment process to identify and address any issues promptly. Monitoring enables early detection of problems, minimizing downtime and ensuring a smooth transition. A combination of automated checks and manual observation provides a comprehensive monitoring strategy.Monitoring the deployment involves several key elements:
- CodeDeploy Console Monitoring: The CodeDeploy console provides real-time status updates on the deployment process. This includes information about the deployment’s progress, the status of each stage, and any errors encountered.
- CloudWatch Metrics and Alarms: CloudWatch metrics are automatically generated for Lambda functions, including invocation counts, error rates, and latency. Setting up CloudWatch alarms based on these metrics allows for automated detection of performance degradation or failures.
- Example: An alarm can be configured to trigger if the error rate of the new Lambda function in the green environment exceeds a predefined threshold (e.g., 1% of invocations).
This triggers an alert to the operations team.
- Example: An alarm can be configured to trigger if the error rate of the new Lambda function in the green environment exceeds a predefined threshold (e.g., 1% of invocations).
- Application Logs: Logging is crucial for debugging and troubleshooting. The Lambda function logs should be sent to CloudWatch Logs. These logs provide detailed information about the function’s execution, including any errors, warnings, and informational messages.
- Health Checks: Health checks, integrated into the deployment process or configured through API Gateway, can verify the health of the green environment. These checks can be automated to ensure that the new Lambda function is functioning correctly before traffic is shifted.
- Example: A health check could involve invoking a specific endpoint in the Lambda function and verifying that it returns the expected response.
- Notifications: Configuring notifications (e.g., through Amazon SNS) allows for alerts to be sent when the deployment status changes or when alarms are triggered. This ensures that the operations team is promptly informed of any issues.
Shifting Traffic from Blue to Green
Shifting traffic is the culmination of the deployment process, marking the transition from the old (blue) environment to the new (green) environment. This shift is typically accomplished through an alias update within Lambda, managed by CodeDeploy.The traffic shifting process generally follows these steps:
- CodeDeploy Updates the Alias: After the deployment is successful, CodeDeploy updates the Lambda function alias to point to the new version of the Lambda function in the green environment. This is the critical step that redirects live traffic.
- Gradual Traffic Shifting (Optional): Depending on the configuration, traffic can be shifted gradually using CodeDeploy’s built-in traffic shifting capabilities. This allows for a phased rollout, where a small percentage of traffic is directed to the green environment initially, and then gradually increased over time. This strategy helps minimize the impact of any potential issues with the new version.
- Example: CodeDeploy can be configured to shift 10% of traffic to the green environment initially, then increase to 50%, and finally to 100%, over a specified period.
- Verification after Traffic Shift: After the traffic shift, thorough verification is essential. This includes:
- Monitoring Metrics: Continuously monitoring the performance metrics (invocation count, error rate, latency) of the new Lambda function in the green environment to ensure that it is performing as expected.
- Functional Testing: Running functional tests against the green environment to validate that the application is behaving correctly.
- User Feedback: Gathering user feedback to identify any issues that may not be apparent from the automated tests.
- Rollback Strategy: Having a well-defined rollback strategy is critical. If any issues are detected after the traffic shift, the alias can be quickly reverted to point back to the blue environment, restoring the previous working version.
Rollback Strategy

Implementing a robust rollback strategy is crucial for mitigating the risks associated with deployment failures in a blue-green architecture. The ability to quickly revert to a stable, known-good state (the blue environment) minimizes downtime, prevents user-facing errors, and maintains service availability. This section details the procedures for rolling back to the blue environment, automating the rollback process, and analyzing failure causes to prevent recurrence.
Manual Rollback Procedure
The manual rollback process provides a step-by-step guide to reverting to the blue environment in case of deployment issues. This procedure is essential when automated rollback fails or when a more granular control is required.
The process typically involves these steps:
- Identify the Failure: The first step is to recognize that the green environment has encountered issues. This can be determined through monitoring tools, user reports, or automated health checks. Failure symptoms include increased error rates, performance degradation, or complete service unavailability.
- Verify the Blue Environment’s Stability: Before initiating the rollback, it is vital to confirm the stability of the blue environment. This involves checking its health metrics and ensuring it is operating as expected. This step prevents rolling back to a potentially unstable blue environment, which would exacerbate the problem.
- Shift Traffic Back to the Blue Environment: This is the core of the rollback process. Using CodeDeploy or the chosen traffic management system, redirect all traffic from the green environment back to the blue environment. This usually involves updating the CodeDeploy deployment group to point to the blue Lambda function version.
- Monitor the Blue Environment: After the traffic shift, continuously monitor the blue environment to ensure it is receiving traffic and functioning correctly. Verify that the service is responding as expected, and error rates are within acceptable limits.
- Decommission the Green Environment: Once the blue environment is confirmed to be stable and handling all traffic, decommission the green environment. This involves deleting the green Lambda function version or removing it from the deployment group, preventing further traffic from being routed to it.
Automated Rollback Procedure
Automating the rollback process significantly reduces the time required to recover from deployment failures, minimizing the impact on users. Automation also eliminates the potential for human error during a stressful situation.
Automated rollback is often implemented using CodeDeploy’s built-in features or through custom scripts integrated with monitoring and alerting systems. Key aspects include:
- Automated Health Checks: Implement comprehensive health checks that monitor the green environment’s performance. These checks should include metrics like error rates, latency, and resource utilization. If any of these metrics exceed predefined thresholds, the automated rollback process is triggered.
- Triggering the Rollback: The monitoring system, upon detecting a failure, triggers the rollback process. This can be achieved through CodeDeploy’s built-in mechanisms, such as the ‘Rollback on Failure’ option in the deployment group configuration, or by invoking a custom Lambda function.
- CodeDeploy Integration: Leverage CodeDeploy’s capabilities to shift traffic back to the blue environment. This typically involves updating the deployment group to point to the blue Lambda function version. CodeDeploy also provides hooks for running pre- and post-traffic-shifting scripts, allowing for more complex rollback procedures.
- Custom Scripting: For more complex scenarios, custom scripts can be used to automate the rollback process. These scripts can interact with the Lambda service, the traffic management system, and other relevant resources. These scripts can also be triggered by the monitoring system or invoked by CodeDeploy.
- Testing the Rollback: Regularly test the automated rollback process to ensure it functions correctly. This involves simulating deployment failures and verifying that the rollback is executed successfully. These tests should be conducted in a non-production environment.
Analyzing Deployment Failures and Prevention
Analyzing the root cause of deployment failures is crucial for preventing similar issues in the future. A thorough investigation helps identify the underlying problems and implement corrective actions.
The analysis process includes these steps:
- Collect and Analyze Logs: Gather logs from the green environment, including Lambda function logs, CloudWatch logs, and any application-specific logs. Analyze these logs to identify error messages, stack traces, and other clues that point to the cause of the failure.
- Examine Metrics and Monitoring Data: Review metrics such as error rates, latency, and resource utilization. Look for patterns and anomalies that correlate with the deployment failure. Tools like CloudWatch provide detailed dashboards and alerts that help in this analysis.
- Reproduce the Failure (if possible): If the failure is reproducible, attempt to replicate it in a testing environment. This allows for a more controlled investigation and facilitates debugging.
- Identify the Root Cause: Determine the underlying cause of the failure. This might involve code errors, configuration issues, resource constraints, or external dependencies. The goal is to pinpoint the exact reason for the failure.
- Implement Corrective Actions: Based on the root cause analysis, implement corrective actions to prevent future failures. This could involve fixing code errors, adjusting configurations, optimizing resource usage, or improving testing procedures.
- Update Deployment Processes: Review and update the deployment process to address any gaps or weaknesses identified during the analysis. This may include improving the health checks, enhancing the rollback mechanism, or adding more comprehensive testing.
- Post-Mortem Reviews: Conduct post-mortem reviews after each deployment failure. These reviews should involve the entire team and focus on identifying lessons learned and action items for improvement. This promotes a culture of continuous improvement.
Advanced Deployment Strategies
Advanced deployment strategies build upon the foundation of blue-green deployments, offering increased flexibility and risk mitigation. These strategies enable more granular control over traffic routing and facilitate safer, more efficient deployments. They are particularly valuable in complex environments and when dealing with high-stakes applications.
Canary Deployments with Lambda and CodeDeploy
Canary deployments involve gradually introducing a new version of a Lambda function to a small subset of traffic before fully transitioning. This approach allows for early detection of issues in production, minimizing the impact of potential failures. CodeDeploy is instrumental in orchestrating this process.To implement a canary deployment using Lambda and CodeDeploy, follow these steps:
- Define the Deployment Group: Create a CodeDeploy deployment group, specifying the Lambda function and the associated aliases (e.g., `$LATEST` and a production alias). The production alias initially points to the current, stable version of the Lambda function.
- Create a New Version: Upload a new version of the Lambda function code. This will be the canary version.
- Configure CodeDeploy for Canary Deployment: Within the CodeDeploy deployment group settings, configure the deployment to shift a small percentage of traffic (e.g., 10%) to the new Lambda version. CodeDeploy uses a traffic-shifting strategy based on weighted traffic.
- Monitor and Validate: After the traffic shift, carefully monitor the performance and behavior of the new Lambda version. Analyze metrics such as error rates, latency, and invocation counts. CodeDeploy provides built-in monitoring capabilities, and you can also integrate with tools like CloudWatch for detailed analysis.
- Automated Rollback: Configure automated rollback triggers in CodeDeploy. If the monitoring reveals any anomalies (e.g., error rates exceeding a predefined threshold), CodeDeploy will automatically roll back to the previous, stable version.
- Gradual Traffic Increase: If the canary version performs satisfactorily, gradually increase the percentage of traffic routed to it over time. This can be achieved by modifying the CodeDeploy deployment settings to increase the traffic weight.
- Full Deployment: Once the canary version has handled a significant portion of the traffic and has proven stable, shift all traffic to the new version and remove the old version, completing the deployment.
A visual representation of this process might show:
Stage 1: Initial Setup
Traffic (100%) -> Production Alias -> Lambda Function (Version A)
Stage 2: Canary Release
Traffic (90%) -> Production Alias -> Lambda Function (Version A)
Traffic (10%) -> Production Alias -> Lambda Function (Version B – Canary)
Stage 3: Validation and Monitoring
Monitor metrics such as error rate, latency, and invocation count. If metrics meet threshold, proceed to next stage.
Stage 4: Gradual Increase (Example)
Traffic (80%) -> Production Alias -> Lambda Function (Version A)
Traffic (20%) -> Production Alias -> Lambda Function (Version B – Canary)
Stage 5: Full Deployment
Traffic (100%) -> Production Alias -> Lambda Function (Version B – New Version)
Comparison of Traffic-Shifting Methods
Different traffic-shifting methods offer varying degrees of control and suitability for different deployment scenarios. Two common methods are weighted traffic and percentage-based traffic.
- Weighted Traffic: This method assigns weights to different versions of a Lambda function, representing the proportion of traffic each version receives. CodeDeploy primarily utilizes weighted traffic.
- Percentage-Based Traffic: Similar to weighted traffic, this method defines the percentage of traffic that should be directed to each version.
The choice between these methods depends on the specific requirements of the deployment:
- Weighted Traffic: Provides fine-grained control over traffic distribution, allowing for precise adjustments. It is well-suited for canary deployments and scenarios where gradual traffic shifts are required. The downside is that it might require more configuration and monitoring.
- Percentage-Based Traffic: Offers a simpler approach, particularly useful for simpler deployments where a fixed percentage of traffic can be shifted. This method is straightforward to implement and understand.
Consider a scenario where a new version of a Lambda function is being deployed. Using weighted traffic, one might initially assign 5% of traffic to the new version and 95% to the existing version. After successful testing, the weights can be adjusted to 20% and 80%, respectively, before a full transition. In contrast, percentage-based traffic could simply shift 10% of the traffic initially, then increase it to 25%, and finally to 100%.
Integrating Blue-Green Deployments with CI/CD Pipelines
Integrating blue-green deployments with CI/CD pipelines automates the entire deployment process, improving efficiency and reducing manual intervention. This integration involves incorporating the deployment steps into the CI/CD workflow.Here’s how to integrate blue-green deployments into a CI/CD pipeline:
- Automated Build and Test: The CI/CD pipeline starts with building the application code and running automated tests. This ensures that the code is functional and meets quality standards before deployment.
- Infrastructure as Code (IaC): Define the infrastructure required for the blue and green environments using IaC tools like AWS CloudFormation or Terraform. This allows for consistent and repeatable infrastructure deployments.
- Automated Deployment: Configure the CI/CD pipeline to automatically deploy the new Lambda function version to the green environment (or the “inactive” environment in a blue-green setup). CodeDeploy can be integrated into the pipeline to manage the deployment process.
- Automated Testing and Validation: After deploying to the green environment, the pipeline should run automated tests to validate the new version. These tests can include unit tests, integration tests, and end-to-end tests.
- Traffic Shifting and Monitoring: Once the tests pass, the pipeline can initiate the traffic shift to the green environment. The pipeline should also include monitoring to track the performance of the new version and automatically roll back if any issues are detected.
- Rollback Mechanism: The pipeline must incorporate a rollback mechanism to automatically revert to the previous, stable version in case of failures. This can be achieved by re-deploying the blue environment.
- Pipeline Tools: Popular CI/CD tools like AWS CodePipeline, Jenkins, GitLab CI, and CircleCI can be used to orchestrate the entire process.
An example of a pipeline process could include:
1. Code changes are committed to a repository (e.g., GitHub, GitLab).
2. The CI/CD pipeline is triggered (e.g., using AWS CodePipeline).
3. The code is built and tested.
4. Infrastructure changes are applied using CloudFormation or Terraform to deploy the new Lambda function version to the “green” environment.
5. CodeDeploy shifts traffic to the new version.
6. Automated tests are executed to validate the new version.
7. If tests pass, the pipeline continues. If tests fail, CodeDeploy rolls back to the previous version.
8. Monitoring is performed.
Monitoring and Logging
Effective monitoring and logging are crucial components of a successful blue-green deployment strategy for Lambda functions. They provide the necessary insights into the performance and health of both the blue and green environments, allowing for rapid detection and resolution of issues, and ensuring a smooth transition. Proper monitoring and logging practices are essential for validating the new deployment, identifying potential problems, and providing data-driven insights for optimization.
Key Metrics to Monitor
Identifying the appropriate metrics to monitor is paramount to understanding the behavior of Lambda functions during and after a blue-green deployment. These metrics offer a window into the function’s performance, resource utilization, and overall health. Monitoring these metrics helps to assess the success of the deployment and facilitates informed decision-making.
- Invocation Count: This metric represents the number of times the Lambda function is executed. Monitoring invocation counts for both the blue and green environments is critical during the traffic shifting phase. Significant discrepancies can indicate issues with traffic routing or function configuration. For example, if the green environment consistently receives a lower invocation count than expected after a traffic shift, it could indicate problems with the event source configuration or the function’s ability to handle incoming requests.
- Duration: Duration measures the time it takes for the Lambda function to execute, from invocation to completion. Monitoring the duration provides insights into the function’s performance and helps identify potential performance regressions. Comparing the duration of the blue and green environments allows for an evaluation of the impact of the new deployment on function execution time. Increased duration in the green environment, for example, might indicate inefficient code, increased latency from dependencies, or resource contention.
- Error Count: This metric tracks the number of errors that occur during function execution. Monitoring error counts is essential for identifying potential problems with the new deployment. A sudden increase in errors in the green environment after a traffic shift indicates that something is wrong with the new code, configuration, or dependencies. Analyzing error logs provides valuable information for troubleshooting.
- Throttles: Throttling occurs when the Lambda service limits the number of concurrent executions of a function. Monitoring throttles is crucial for ensuring that the function has sufficient resources to handle the workload. If the green environment experiences a high number of throttles, it indicates that the function is exceeding its concurrency limits, potentially impacting performance and user experience.
- Concurrent Executions: This metric tracks the number of instances of the Lambda function that are running concurrently. Monitoring concurrent executions helps to understand the resource utilization of the function and identify potential bottlenecks. A high number of concurrent executions can indicate increased load on the function, potentially leading to performance degradation.
- Memory Utilization: This metric measures the amount of memory used by the Lambda function during execution. Monitoring memory utilization helps to optimize the function’s memory configuration and prevent out-of-memory errors. If the green environment shows significantly higher memory utilization than the blue environment, it could indicate a memory leak or inefficient code in the new deployment.
- Cold Starts: Cold starts occur when a Lambda function needs to initialize a new execution environment. Monitoring cold starts helps to identify and mitigate potential performance issues related to function initialization. A high number of cold starts can increase the function’s execution time and impact the user experience.
Configuring Logging and Monitoring with CloudWatch and X-Ray
CloudWatch and X-Ray are powerful AWS services that provide comprehensive logging and monitoring capabilities for Lambda functions. CloudWatch collects and aggregates logs, metrics, and events, while X-Ray provides detailed tracing information for understanding the flow of requests through distributed applications. Configuring these services effectively is crucial for gaining insights into the performance and health of the Lambda functions.
- CloudWatch Logs: CloudWatch Logs is used to collect, store, and monitor log data from Lambda functions. Logs provide detailed information about function execution, including input, output, errors, and debugging information.
- Log Groups: Each Lambda function automatically creates a log group in CloudWatch Logs. Within each log group, there are log streams for each function execution.
- Log Levels: Lambda functions support different log levels (e.g., DEBUG, INFO, WARNING, ERROR) to control the verbosity of the logging output. Selecting the appropriate log levels allows for efficient troubleshooting.
- Structured Logging: Employing structured logging (e.g., JSON format) makes it easier to parse and analyze log data, allowing for more effective filtering and searching. For example:
console.log(JSON.stringify( "level": "INFO", "message": "Order processed successfully", "orderId": "12345", "customerId": "67890" ));This structured log entry provides clear context and facilitates automated analysis.
- CloudWatch Metrics: CloudWatch Metrics are used to monitor the performance and health of Lambda functions. AWS automatically publishes several metrics, such as invocation count, duration, and error count, to CloudWatch. Custom metrics can also be defined to monitor specific application-related events.
- Custom Metrics: Creating custom metrics provides a mechanism for monitoring business-specific aspects of the Lambda functions. For example, if the function processes payment transactions, a custom metric could track the number of successful transactions.
- Metric Filters: Metric filters can be used to extract specific data from log events and create custom metrics. For example, a metric filter can be created to count the number of times a specific error message appears in the logs.
- X-Ray: X-Ray provides end-to-end tracing of requests as they travel through the Lambda function and any downstream services. It helps to identify performance bottlenecks and troubleshoot issues in distributed applications.
- Instrumentation: To use X-Ray, the Lambda function needs to be instrumented with the X-Ray SDK. The SDK automatically captures traces for each invocation and provides detailed information about the function’s execution.
- Tracing: X-Ray creates traces that represent the flow of requests through the application. Each trace is composed of segments and subsegments, providing detailed information about the execution of each component.
- Service Maps: X-Ray generates service maps that visualize the relationships between different services in the application. This helps to understand the overall architecture and identify potential dependencies.
Visualizing Performance Metrics with Dashboards and Alerts
Creating dashboards and setting up alerts in CloudWatch is critical for gaining a clear understanding of the Lambda function’s performance and for promptly responding to any issues that may arise. Dashboards provide a centralized view of key metrics, while alerts automatically notify when predefined thresholds are breached.
- CloudWatch Dashboards: CloudWatch Dashboards provide a visual representation of the performance metrics. They allow for the creation of customized dashboards that display the most important metrics for monitoring the Lambda functions.
- Metric Widgets: Dashboards are composed of metric widgets that display the data for specific metrics. The widgets can be configured to display different types of charts, such as line graphs, bar charts, and pie charts.
- Real-time Monitoring: Dashboards can be configured to refresh automatically, providing real-time monitoring of the Lambda functions. This allows for the immediate identification of any performance issues.
- Example Dashboard Setup: A dashboard could include widgets for invocation count, duration, error count, concurrent executions, and cold starts. This provides a comprehensive view of the function’s performance.
- CloudWatch Alerts: CloudWatch Alerts automatically trigger notifications when predefined thresholds are breached. They provide a mechanism for proactively identifying and responding to issues.
- Metric Alarms: Alerts are based on metric alarms that monitor the values of specific metrics. For example, an alarm can be created to trigger a notification if the error rate exceeds a certain threshold.
- Notification Channels: Alerts can be configured to send notifications through various channels, such as email, SMS, and Slack. This ensures that the appropriate team members are notified when an issue occurs.
- Example Alert Configuration: An alert could be configured to trigger a notification if the error count exceeds a certain threshold within a specified time period. Another alert could be set up to notify if the function’s duration increases beyond a certain value.
- Data Analysis and Interpretation: Analyzing the data displayed on dashboards and responding to alerts is a critical part of the monitoring process. This involves interpreting the metrics, identifying the root causes of any issues, and taking corrective action. For example, an increase in the duration metric might indicate an issue with the code that is affecting performance. The team could analyze the code, optimize it, and then redeploy.
Security Considerations
Implementing blue-green deployments for Lambda functions introduces specific security challenges that must be addressed to maintain the confidentiality, integrity, and availability of your applications. This section details security best practices, provides examples of securing Lambda functions during deployment, and Artikels procedures for reviewing and auditing the deployment process to ensure compliance with security standards. A proactive approach to security is critical throughout the blue-green deployment lifecycle, from initial setup to ongoing monitoring.
Access Control and Permissions
Proper access control is paramount to prevent unauthorized access and manipulation of Lambda functions and associated resources. This involves implementing the principle of least privilege, granting only the necessary permissions to users, roles, and services.
- IAM Roles: Each Lambda function should be assigned an IAM role with the minimum required permissions. Avoid using the ‘AdministratorAccess’ policy. Instead, define granular policies that allow access to specific AWS services and resources. For example, if a Lambda function reads data from an S3 bucket, its IAM role should only have read access to that specific bucket, not all S3 buckets.
- Resource-Based Policies: Use resource-based policies on resources like S3 buckets, DynamoDB tables, and API Gateway to restrict access based on the identity of the caller. This adds an extra layer of security, ensuring that only authorized Lambda functions can access these resources.
- Deployment Pipelines: Secure your deployment pipelines by restricting access to sensitive information like API keys, database credentials, and secrets. Implement robust authentication and authorization mechanisms for your deployment tools.
- Code Signing: Consider using AWS Code Signing for Lambda functions to verify the integrity and origin of the code deployed. This ensures that the code hasn’t been tampered with and comes from a trusted source. Code signing helps to prevent the deployment of malicious code.
Data Encryption
Data encryption is crucial to protect sensitive data both at rest and in transit. Implementing encryption mechanisms helps to safeguard against data breaches and unauthorized access.
- Encryption at Rest: Encrypt data stored in S3 buckets, DynamoDB tables, and other data stores using server-side encryption (SSE) or client-side encryption (CSE). SSE uses keys managed by AWS or by you, while CSE requires you to manage the encryption keys. AWS Key Management Service (KMS) can be used to manage encryption keys.
- Encryption in Transit: Use HTTPS for all communication between Lambda functions and external services. This encrypts the data in transit, protecting it from eavesdropping.
- Environment Variables: Store sensitive information like API keys, database credentials, and other secrets in AWS Secrets Manager or Parameter Store. Avoid hardcoding secrets in your Lambda function code. Access these secrets using the AWS SDK within your Lambda function.
- KMS Integration: Integrate your Lambda functions with KMS to encrypt and decrypt data. This is particularly useful for protecting sensitive data within your function code or when storing data in encrypted formats. For example, a Lambda function could encrypt a customer’s credit card number before storing it in a database.
Security Best Practices During Deployment
The deployment process itself must be secured to prevent vulnerabilities and ensure the integrity of the application. Following these practices can help mitigate security risks during the blue-green deployment.
- Immutable Infrastructure: Treat your infrastructure as immutable. This means that once a Lambda function is deployed, it should not be modified directly. Instead, deploy a new version with the necessary changes. This reduces the risk of configuration drift and simplifies rollback procedures.
- Automated Security Scanning: Integrate security scanning tools into your deployment pipeline. These tools can automatically scan your Lambda function code and dependencies for vulnerabilities.
- Vulnerability Management: Regularly update your Lambda function dependencies to patch known vulnerabilities. Use tools like Dependabot or Snyk to automate the process of identifying and updating dependencies.
- Least Privilege for Deployment Tools: Grant deployment tools, such as CodeDeploy, the minimum required permissions to deploy and manage Lambda functions. Avoid giving them excessive privileges that could be exploited.
- Secret Management: Securely manage secrets used during the deployment process. Never store secrets in your code repository or deployment scripts. Use services like AWS Secrets Manager to store and retrieve secrets.
Reviewing and Auditing the Deployment Process
Regularly reviewing and auditing the deployment process is essential to ensure compliance with security policies and identify potential vulnerabilities.
- Deployment Logs: Maintain detailed deployment logs that capture all actions taken during the deployment process. These logs should include information about the user or service that initiated the deployment, the changes made, and any errors encountered.
- Audit Trails: Enable CloudTrail to log all API calls made to your AWS account. This provides a comprehensive audit trail of all actions taken, including deployments, configuration changes, and access to resources.
- Regular Security Audits: Conduct regular security audits of your blue-green deployment process. These audits should assess the security posture of your Lambda functions, deployment pipelines, and infrastructure.
- Compliance Checks: Implement automated compliance checks to ensure that your deployments comply with security standards and regulations. This can include checking for vulnerabilities, verifying access control policies, and ensuring that data is encrypted.
- Incident Response Plan: Develop and maintain an incident response plan to address security incidents that may occur during the deployment process or after deployment. This plan should Artikel the steps to be taken to contain, eradicate, and recover from a security incident.
Troubleshooting Common Issues
Implementing blue-green deployments for AWS Lambda functions, while offering significant advantages, can present challenges. A structured approach to troubleshooting is essential to quickly identify, diagnose, and resolve issues that may arise during deployment and traffic shifting. This section Artikels a comprehensive troubleshooting guide to address common problems.
Function Configuration Issues
Function configuration errors are a frequent cause of deployment failures and unexpected behavior. These issues can stem from incorrect settings in the Lambda function itself, its associated configuration, or its interaction with other AWS services.
- Incorrect Handler Specification: The handler function, specified during function creation, dictates the entry point of the Lambda function. If the handler is misconfigured, the function may fail to execute.
- Error Message Example: ”
Handler 'my_function.handler' not found“. - Potential Cause: The handler string in the Lambda function configuration (e.g., `my_module.my_function`) doesn’t accurately reflect the file and function name within the deployed code.
- Resolution: Verify the handler string in the Lambda console or deployment configuration (e.g., CloudFormation, SAM) against the actual function name and file path in your code. Ensure the function is accessible and correctly named.
- Memory and Timeout Settings: Insufficient memory or a short timeout period can lead to function failures, particularly under heavy load or for complex operations.
- Error Message Example: ”
Task timed out after 3 seconds” or ”OutOfMemoryError“. - Potential Cause: The function’s allocated memory is too low, or the execution time exceeds the configured timeout.
- Resolution: Gradually increase the memory allocation (e.g., starting with 128MB and increasing incrementally) and timeout settings in the Lambda configuration. Monitor performance metrics (e.g., execution time, memory utilization) in CloudWatch to optimize these settings. For example, consider increasing the timeout to 30 seconds, or even more, depending on the application’s requirements.
- Environment Variables: Incorrectly configured or missing environment variables can lead to runtime errors.
- Error Message Example: ”
KeyError: 'DATABASE_URL'” or ”Invalid configuration“. - Potential Cause: The function code relies on environment variables that are either not set or have incorrect values.
- Resolution: Review the function’s environment variable configuration in the Lambda console or deployment configuration. Verify that all required variables are defined and contain the correct values. Consider using a secrets management solution (e.g., AWS Secrets Manager) to securely store sensitive information.
- Incorrect Runtime: Using an unsupported or mismatched runtime version can prevent the function from executing correctly.
- Error Message Example: ”
Runtime 'nodejs18.x' is not supported“. - Potential Cause: The Lambda function is configured to use a runtime version that is no longer supported by AWS or is incompatible with the deployed code.
- Resolution: Review the AWS Lambda documentation to determine supported runtimes. Update the Lambda function’s runtime setting to a supported version that is compatible with your code. Regularly update the runtime to leverage the latest security patches and performance improvements.
IAM Permissions Issues
Insufficient or incorrectly configured IAM permissions are a common source of errors, preventing Lambda functions from accessing necessary AWS resources.
- Missing Permissions: The Lambda function’s execution role requires the necessary permissions to interact with other AWS services (e.g., S3, DynamoDB, API Gateway).
- Error Message Example: ”
An error occurred (AccessDeniedException) when calling the PutObject operation on the S3 bucket“. - Potential Cause: The Lambda function’s execution role does not have the required permissions to perform a specific action on a particular AWS resource.
- Resolution: Review the Lambda function’s execution role and add the necessary IAM permissions. Utilize the principle of least privilege, granting only the minimum permissions required for the function to operate. Use the AWS IAM console or infrastructure-as-code tools (e.g., Terraform, CloudFormation) to manage permissions.
- Incorrect Resource Policies: Resource policies on AWS resources (e.g., S3 buckets, API Gateway endpoints) may restrict access to the Lambda function.
- Error Message Example: ”
User: arn:aws:sts::123456789012:assumed-role/my-lambda-role is not authorized to perform: s3:GetObject on resource: arn:aws:s3:::my-bucket/my-object“. - Potential Cause: The resource policy on the target resource does not grant the Lambda function’s execution role access.
- Resolution: Verify the resource policy on the affected AWS resources and ensure that it allows access from the Lambda function’s execution role. Update the resource policy to grant the necessary permissions. Carefully review the policy statements to avoid inadvertently granting excessive permissions.
- Cross-Account Access: When a Lambda function needs to access resources in a different AWS account, the IAM permissions and resource policies must be configured correctly.
- Error Message Example: ”
An error occurred (AccessDeniedException) when calling the PutObject operation on the S3 bucket“. - Potential Cause: The Lambda function in one account lacks the necessary permissions to access the resources in another account, or the resource policy in the target account does not allow access from the source account.
- Resolution: Configure the IAM role in the source account to trust the Lambda function’s service principal. In the target account, create a resource policy on the affected resources that allows access from the source account’s IAM role. Use a cross-account IAM role with appropriate permissions for the Lambda function.
Traffic Shifting Issues
Errors in traffic shifting configuration can lead to unexpected behavior, including traffic not being routed to the new version of the function or issues with the deployment itself.
- CodeDeploy Configuration Errors: Incorrectly configured CodeDeploy deployments can lead to failures during traffic shifting.
- Error Message Example: ”
Deployment failed during traffic shifting“. - Potential Cause: Issues with the CodeDeploy application, deployment group, or deployment configuration.
- Resolution: Review the CodeDeploy configuration in the AWS console or deployment configuration files (e.g., `appspec.yml`). Ensure that the application and deployment group are correctly configured. Verify that the deployment group is associated with the correct Lambda function alias and that the traffic shifting configuration (e.g., linear or canary) is accurate. Check the CloudWatch logs for CodeDeploy to identify specific error messages.
- Alias Configuration Problems: Lambda function aliases play a crucial role in blue-green deployments. Incorrect alias configuration can lead to deployment failures.
- Error Message Example: ”
Invalid alias name” or ”Alias does not exist“. - Potential Cause: The Lambda function alias is not created or is misconfigured, preventing CodeDeploy from correctly updating the traffic distribution.
- Resolution: Verify that the Lambda function alias exists and is correctly configured. The alias should point to the desired function version (e.g., the “green” version). Ensure that the alias name used in the CodeDeploy configuration matches the actual alias name. Consider using a dedicated alias for deployments (e.g., “staging”) to manage traffic shifting.
- Traffic Weighting Issues: Problems with traffic distribution can result in some users still accessing the old function version after a successful deployment.
- Error Message Example: ”
Traffic is still being routed to the old function version“. - Potential Cause: The traffic weighting settings in the CodeDeploy deployment group are not correctly configured, or there is a delay in the traffic shifting process.
- Resolution: Review the traffic weighting settings in the CodeDeploy deployment group. Ensure that the weights are set to shift traffic to the new function version gradually (e.g., using a canary deployment) or immediately (e.g., for a full blue-green switch). Monitor the CloudWatch metrics for the Lambda function to verify that traffic is being routed to the correct version. Consider waiting for the traffic shift to complete before proceeding with further steps.
Process for Issue Identification and Resolution
A systematic approach to identifying and resolving issues is essential. This process combines monitoring, logging, and debugging techniques.
- Monitoring: Implement comprehensive monitoring to detect issues.
- Action: Configure CloudWatch metrics and alarms for the Lambda function, including invocation errors, execution time, and memory utilization. Use CloudWatch dashboards to visualize the performance of the blue and green versions. Set up alerts for critical metrics.
- Example: Create an alarm that triggers when the error rate exceeds 1% for the green function version after deployment.
- Action: Configure structured logging within the Lambda function code to include timestamps, request IDs, and relevant context. Route logs to CloudWatch Logs. Utilize log groups and log streams for organization.
- Example: Log the input parameters, environment variables, and any exceptions encountered within the function.
- Action: Examine CloudWatch Logs for error messages, stack traces, and other relevant information. Correlate errors with specific deployments or traffic shifts. Use CloudWatch Insights to query and analyze logs.
- Example: If a function is throwing an exception, examine the stack trace to pinpoint the source of the error. Look for common patterns in the logs.
- Action: Utilize local testing with the AWS SAM CLI or other tools to simulate the Lambda function’s execution environment. Enable X-Ray tracing to track requests across the function’s execution path. Use print statements or a debugger to step through the code and identify the source of the problem.
- Example: Use X-Ray to visualize the execution flow and identify bottlenecks or errors in downstream services.
- Action: Implement a rollback strategy to revert to the previous stable function version if issues are detected. This often involves shifting traffic back to the blue version.
- Example: If the green version is experiencing errors, immediately shift traffic back to the blue version by updating the traffic weights in the CodeDeploy deployment group.
- Action: Document the root cause of any issues encountered, along with the steps taken to resolve them. Implement preventative measures to avoid similar issues in the future.
- Example: If a missing IAM permission caused a deployment failure, document the missing permission and add it to the function’s IAM role definition.
Final Review
In conclusion, mastering how to implement blue-green deployments for Lambda is a key factor in achieving high availability, rapid iteration, and enhanced application stability. By adopting the strategies Artikeld, developers can minimize risk, improve user experience, and streamline their serverless deployments. From traffic shifting with CodeDeploy to advanced canary releases, this guide provides a solid foundation for building resilient and scalable Lambda-based applications, encouraging a shift towards more robust and efficient deployment practices.
Questions Often Asked
What is the primary benefit of using blue-green deployments with Lambda?
The primary benefit is zero-downtime deployments, enabling continuous updates without disrupting user access to the application.
How does CodeDeploy facilitate traffic shifting in a blue-green deployment for Lambda?
CodeDeploy manages the gradual or immediate transition of traffic between the blue (old) and green (new) Lambda function versions based on the defined deployment configuration.
What are some common causes of deployment failures in blue-green Lambda deployments?
Common causes include incorrect function configurations, IAM permission issues, code errors in the new version, and problems with traffic shifting settings.
How can I automate the rollback process in case of a deployment failure?
The rollback can be automated using CodeDeploy by configuring the deployment to automatically revert to the blue environment if health checks fail or errors are detected during the green deployment.